
Главное меню
Навигация
Настраиваем с нуля
Цикл статей Настройка Call Manager Express CUCME с нуля:
Цикл статей Настройка Call Manager CUCM с нуля:
Comunications Apps с нуля
UCCX
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 1
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 2
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 3
- Настройка UCCX 10.x, 11.x + Cisco Finesse desktop
- Установка скрипта для записи UCCX Prompts
CUC
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 1
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 2
CUP
- Настройка Cisco Unified Presence (CUP) с нуля. Теория
- Настройка Cisco Unified Presence (CUP) с нуля. Практика: Начальная установка
MediaSense
Настройка комплекта Cisco CUCM Business Edition 6000
- Настройка комплекта BE6000: Введение
- Настройка комплекта BE6000: Установка CUCM 11
- Настройка комплекта BE6000: Начальная установка CUC 11
- Настройка комплекта BE6000: Немного теории CUC 11
- Настройка комплекта BE6000: Настраиваем своего автосекретаря (IVR) в CUC 11
- Настройка комплекта BE6000: правильная Архивация CUCM 11.5
- Настройка комплекта BE6000: Восстановление CUCM 11.5 из архива
- Настройка комплекта BE6000: устанавливаем лицензии для телефонов CUCM 11.5
- Настройка комплекта BE6000: настройка конференции ad hoc CUCM 11.5
- Настройка комплекта BE6000: настройка конференции meet-me CUCM 11.5
- Настройка комплекта BE6000: настройка мониторинга комплекса CUCM 11.5
CUCM в крупном предприятии
- SRST. Теория (часть 1)
- SRST: Практика (Часть 2)
- Диалплан (dialplan) в крупной организации
- Cisco Device Mobility. Теория
- Cisco Device Mobility. Настройка
- Cisco Extension Mobility. Теория
- Cisco Extension Mobility. Настройка
- Call Control Discovery
- Настройка Multicast MOH Server на маршрутизаторах филиалов
- Cisco H.323 Gatekeeper. Теория
- Cisco H.323 Gatekeeper. Настройка и Практика
- Cisco H.323 Gatekeeper и Call Admission Control
- Практика подключения H.323 и SIP с использованием CUBE
- CUCM и LDAP Integration
DTMF и его настройка
Вы здесь
Python. 1.1 Типы данных в Python
Числа
С числами можно выполнять различные математические операции.
In [9]: 1+2 Out[9]: 3
С помощью функции round можно округлять числа до нужного количества знаков:
In [10]: round(10/3.0, 2) Out[10]: 3.33
Операторы сравнения
In [11]: 10 > 3.0 Out[11]: True
Функция int() позволяет выполнять конвертацию в тип int. Во втором аргументе можно указывать систему счисления:
In [12]: a = '11' In [13]: int(a) Out[13]: 11
Если указать, что строку a надо воспринимать как двоичное число, то результат будет таким:
In [14]: int(a, 2) Out[14]: 3
Конвертация в int типа float:
In [19]: int(3.333) Out[19]: 3
Функция bin позволяет получить двоичное представление числа (обратите внимание, что результат - строка):
In [20]: bin(8) Out[20]: '0b1000'
Аналогично, функция hex() позволяет получить шестнадцатеричное значение:
In [21]: hex(10) Out[21]: '0xa'
несколько преобразований одновременно:
In [23]: int('ff', 16) Out[23]: 255 In [24]: bin(int('ff', 16)) Out[24]: '0b11111111'
Для более сложных математических функций в Python есть модуль math:
In [25]: import math In [26]: math.sqrt(9) Out[26]: 3.0 In [27]: math.pi Out[27]: 3.141592653589793
Строки (Strings)
Строка в Python это:
- последовательность символов, заключенная в кавычки
- неизменяемый упорядоченный тип данных
Примеры:
In [28]: 'hello' Out[28]: 'hello' In [29]: tunnel = """ ...: interface Tunnel0 ...: ip address 10.10.10.1 255.255.255.0 ...: tunnel source FastEthernet1/0 ...: tunnel protection ipsec profile DMVPN ...: """ In [30]: tunnel Out[30]: '\ninterface Tunnel0\nip address 10.10.10.1 255.255.255.0\ntunnel source FastEthernet1/0\ntunnel protection ipsec profile DMVPN\n'
Строки можно суммировать. Тогда они объединяются в одну строку:
In [32]: intf = 'interface' In [33]: tun = 'Tunnel0' In [34]: intf + tun Out[34]: 'interfaceTunnel0' In [35]: intf + ' ' + tun Out[35]: 'interface Tunnel0'
Строку можно умножать на число. В этом случае, строка повторяется указанное количество раз:
In [36]: intf * 5 Out[36]: 'interfaceinterfaceinterfaceinterfaceinterface'
То, что строки являются упорядоченным типом данных, позволяет обращаться к символам в строке по номеру, начиная с нуля:
In [37]: string1 = 'interface FastEthernet1/0' In [38]: string1[0] Out[38]: 'i'
Нумерация всех символов в строке идет с нуля. Но, если нужно обратиться к какому-то по счету символу, начиная с конца, то можно указывать отрицательные значения (на этот раз с единицы).
In [39]: string1[1] Out[39]: 'n' In [40]: string1[-1] Out[40]: '0'
Кроме обращения к конкретному символу, можно делать срезы строк, указав диапазон номеров (срез выполняется по второе число, не включая его):
In [41]: string1[0:9] Out[41]: 'interface' In [42]: string1[10:22] Out[42]: 'FastEthernet'
Если не указывается второе число, то срез будет до конца строки:
In [26]: string1[10:] Out[26]: 'FastEthernet1/0'
Срезать три последних символа строки:
In [43]: string1[-3:] Out[43]: '1/0'
Также в срезе можно указывать шаг. Так можно получить нечетные числа:
In [44]: a = '0123456789' In [45]: a[1::2] Out[45]: '13579'
In [31]: a[::2] Out[31]: '02468'
Функция len позволяет получить количество символов в строке:
In [46]: line = 'interface Gi0/1' In [47]: len(line) Out[47]: 15
Функция и метод отличаются тем, что метод привязан к объекту конкретного типа, а функция, как правило, более универсальная и может применяться к объектам разного типа. Например, функция len может применяться к строкам, спискам, словарям и так далее, а метод startswith относится только к строкам.
Методы upper, lower, swapcase, capitalize
Методы upper(), lower(), swapcase(), capitalize() выполняют преобразование регистра строки:
In [25]: string1 = 'FastEthernet' In [26]: string1.upper() Out[26]: 'FASTETHERNET' In [27]: string1.lower() Out[27]: 'fastethernet' In [28]: string1.swapcase() Out[28]: 'fASTeTHERNET' In [29]: string2 = 'tunnel 0' In [30]: string2.capitalize() Out[30]: 'Tunnel 0'
Очень важно обращать внимание на то, что часто методы возвращают преобразованную строку. И, значит, надо не забыть присвоить ее какой-то переменной (можно той же).
In [31]: string1 = string1.upper() In [32]: print(string1) FASTETHERNET
Метод count
Метод count() используется для подсчета того, сколько раз символ или подстрока встречаются в строке:
In [33]: string1 = 'Hello, hello, hello, hello' In [34]: string1.count('hello') Out[34]: 3 In [35]: string1.count('ello') Out[35]: 4 In [36]: string1.count('l') Out[36]: 8
Метод find
Методу find() можно передать подстроку или символ, и он покажет, на какой позиции находится первый символ подстроки (для первого совпадения):
In [37]: string1 = 'interface FastEthernet0/1' In [38]: string1.find('Fast') Out[38]: 10 In [39]: string1[string1.find('Fast')::] Out[39]: 'FastEthernet0/1'
Методы startswith, endswith
Проверка на то, начинается или заканчивается ли строка на определенные символы (методы startswith(), endswith()):
In [40]: string1 = 'FastEthernet0/1' In [41]: string1.startswith('Fast') Out[41]: True In [42]: string1.startswith('fast') Out[42]: False In [43]: string1.endswith('0/1') Out[43]: True In [44]: string1.endswith('0/2') Out[44]: False
Методам startswith() и endswith() можно передавать несколько значений (обязательно как кортеж):
In [1]: "test".startswith(("r", "t")) Out[1]: True In [2]: "test".startswith(("r", "a")) Out[2]: False In [3]: "rtest".startswith(("r", "a")) Out[3]: True In [4]: "rtest".endswith(("r", "a")) Out[4]: False In [5]: "rtest".endswith(("r", "t")) Out[5]: True
Метод replace
Замена последовательности символов в строке на другую последовательность (метод replace()):
In [45]: string1 = 'FastEthernet0/1' In [46]: string1.replace('Fast', 'Gigabit') Out[46]: 'GigabitEthernet0/1'
Метод strip
Часто при обработке файла файл открывается построчно. Но в конце каждой строки, как правило, есть какие-то спецсимволы (а могут быть и в начале). Например, перевод строки.
Для того, чтобы избавиться от них, очень удобно использовать метод strip():
In [47]: string1 = '\n\tinterface FastEthernet0/1\n' In [48]: print(string1) interface FastEthernet0/1 In [49]: string1 Out[49]: '\n\tinterface FastEthernet0/1\n' In [50]: string1.strip() Out[50]: 'interface FastEthernet0/1'
По умолчанию метод strip() убирает пробельные символы. В этот набор символов входят: \t\n\r\f\v
Методу strip можно передать как аргумент любые символы. Тогда в начале и в конце строки будут удалены все символы, которые были указаны в строке:
In [51]: ad_metric = '[110/1045]' In [52]: ad_metric.strip('[]') Out[52]: '110/1045'
Метод strip() убирает спецсимволы и в начале, и в конце строки. Если необходимо убрать символы только слева или только справа, можно использовать, соответственно, методы lstrip() и rstrip().
Метод split
Метод split() разбивает строку на части, используя как разделитель какой-то символ (или символы) и возвращает список строк:
In [53]: string1 = 'switchport trunk allowed vlan 10,20,30,100-200' In [54]: commands = string1.split() In [55]: print(commands) ['switchport', 'trunk', 'allowed', 'vlan', '10,20,30,100-200']
По умолчанию в качестве разделителя используются пробельные символы (пробелы, табы, перевод строки), но в скобках можно указать любой разделитель:
In [56]: vlans = commands[-1].split(',') In [57]: print(vlans) ['10', '20', '30', '100-200']
Полезная особенность метода split с разделителем по умолчанию — строка не только разделяется в список строк по пробельным символам, но пробельные символы также удаляются в начале и в конце строки:
In [58]: string1 = ' switchport trunk allowed vlan 10,20,30,100-200\n\n' In [59]: string1.split() Out[59]: ['switchport', 'trunk', 'allowed', 'vlan', '10,20,30,100-200']
У метода split() есть ещё одна хорошая особенность: по умолчанию метод разбивает строку не по одному пробельному символу, а по любому количеству.
Форматирование строк
При работе со строками часто возникают ситуации, когда в шаблон строки надо подставить разные данные.
Это можно делать объединяя, части строки и данные, но в Python есть более удобный способ — форматирование строк.
Форматирование строк может помочь, например, в таких ситуациях:
- необходимо подставить значения в строку по определенному шаблону
- необходимо отформатировать вывод столбцами
- надо конвертировать числа в двоичный формат
Существует несколько вариантов форматирования строк:
- с оператором % — более старый вариант
- метод format() — относительно новый вариант
f- -строки — новый вариант, который появился в Python 3.6.
Несмотря на то, что рекомендуется использовать метод format, часто можно встретить форматирование строк и через оператор %.
Форматирование строк с методом format
Пример использования метода format:
In [1]: "interface FastEthernet0/{}".format('1') Out[1]: 'interface FastEthernet0/1'
Специальный символ {} указывает, что сюда подставится значение, которое передается методу format. При этом каждая пара фигурных скобок обозначает одно место для подстановки.
Значения, которые подставляются в фигурные скобки, могут быть разного типа. Например, это может быть строка, число или список:
In [3]: print('{}'.format('10.1.1.1')) 10.1.1.1 In [4]: print('{}'.format(100)) 100 In [5]: print('{}'.format([10, 1, 1,1])) [10, 1, 1, 1]
С помощью форматирования строк можно выводить результат столбцами. В форматировании строк можно указывать, какое количество символов выделено на данные. Если количество символов в данных меньше, чем выделенное количество символов, недостающие символы заполняются пробелами.
Например, таким образом можно вывести данные столбцами одинаковой ширины по 15 символов с выравниванием по правой стороне:
In [3]: vlan, mac, intf = ['100', 'aabb.cc80.7000', 'Gi0/1'] In [4]: print("{:>15} {:>15} {:>15}".format(vlan, mac, intf)) 100 aabb.cc80.7000 Gi0/1
Выравнивание по левой стороне:
In [5]: print("{:15} {:15} {:15}".format(vlan, mac, intf)) 100 aabb.cc80.7000 Gi0/1
Шаблон для вывода может быть и многострочным:
In [6]: ip_template = ''' ...: IP address: ...: {} ...: ''' In [7]: print(ip_template.format('10.1.1.1')) IP address: 10.1.1.1
С помощью форматирования строк можно также влиять на отображение чисел.
Например, можно указать, сколько цифр после запятой выводить:
In [9]: print("{:.3f}".format(10.0/3)) 3.333
С помощью форматирования строк можно конвертировать числа в двоичный формат:
In [11]: '{:b} {:b} {:b} {:b}'.format(192, 100, 1, 1) Out[11]: '11000000 1100100 1 1'
In [12]: '{:8b} {:8b} {:8b} {:8b}'.format(192, 100, 1, 1) Out[12]: '11000000 1100100 1 1'
А также можно указать, что надо дополнить числа нулями, вместо пробелов:
In [13]: '{:08b} {:08b} {:08b} {:08b}'.format(192, 100, 1, 1) Out[13]: '11000000 01100100 00000001 00000001'
В фигурных скобках можно указывать имена. Это позволяет передавать аргументы в любом порядке, а также делает шаблон более понятным:
In [15]: '{ip}/{mask}'.format(mask=24, ip='10.1.1.1') Out[15]: '10.1.1.1/24'
Еще одна полезная возможность форматирования строк - указание номера аргумента:
In [16]: '{1}/{0}'.format(24, '10.1.1.1') Out[16]: '10.1.1.1/24'
За счет этого, например, можно избавиться от повторной передачи одних и тех же значений: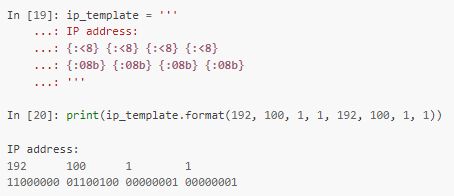
В примере выше октеты адреса приходится передавать два раза - один для отображения в десятичном формате, а второй - для двоичного.
Указав индексы значений, которые передаются методу format, можно избавиться от дублирования: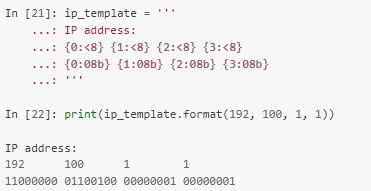
Форматирование строк с помощью f-строк
В Python 3.6 добавился новый вариант форматирования строк - f-строки или интерполяция строк. F-строки позволяют не только подставлять какие-то значения в шаблон, но и позволяют выполнять вызовы функций, методов и т.п.
Во многих ситуациях f-строки удобней и проще использовать, чем format, кроме того, f-строки работают быстрее, чем format и другие методы форматирования строк.
F-строки — это литерал строки с буквой f перед ним. Внутри f-строки в паре фигурных скобок указываются имена переменных, которые надо подставить:
In [1]: ip = '10.1.1.1' In [2]: mask = 24 In [3]: f"IP: {ip}, mask: {mask}" Out[3]: 'IP: 10.1.1.1, mask: 24' Аналогичный результат с format можно получить так: ``"IP: {ip}, mask: {mask}".format(ip=ip, mask=mask)``.
Очень важное отличие f-строк от format: f-строки — это выражение, которое выполняется, а не просто строка. То есть, в случае с ipython, как только мы написали выражение и нажали Enter, оно выполнилось и вместо выражений {ip} и {mask} подставились значения переменных.
Поэтому, например, нельзя сначала написать шаблон, а затем определить переменные, которые используются в шаблоне:
In [1]: f"IP: {ip}, mask: {mask}" --------------------------------------------------------------------------- NameError Traceback (most recent call last)in () ----> 1 f"IP: {ip}, mask: {mask}" NameError: name 'ip' is not defined
Кроме подстановки значений переменных, в фигурных скобках можно писать выражения:
In [5]: first_name = 'William' In [6]: second_name = 'Shakespeare' In [7]: f"{first_name.upper()} {second_name.upper()}" Out[7]: 'WILLIAM SHAKESPEARE'
После двоеточия в f-строках можно указывать те же значения, что и при использовании format: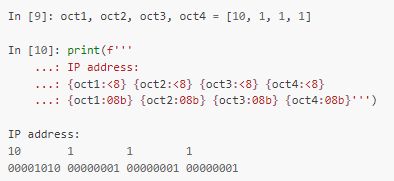
Объединение литералов строк
В Python есть очень удобная функциональность — объединение литералов строк.
In [1]: s = ('Test' 'String') In [2]: s Out[2]: 'TestString' In [3]: s = 'Test' 'String' In [4]: s Out[4]: 'TestString'
Можно даже переносить составляющие строки на разные строки, но только если они в скобках:
In [5]: s = ('Test' ...: 'String') In [6]: s Out[6]: 'TestString'
Этим очень удобно пользоваться в регулярных выражениях
Так регулярное выражение можно разбивать на части и его будет проще понять. Плюс можно добавлять поясняющие комментарии в строках.
regex = ('(\S+) +(\S+) +' # interface and IP '\w+ +\w+ +' '(up|down|administratively down) +' # Status '(\w+)') # Protocol
Также этим приемом удобно пользоваться, когда надо написать длинное сообщение:
In [7]: message = ('При выполнении команды "{}" ' ...: 'возникла такая ошибка "{}".\n' ...: 'Исключить эту команду из списка? [y/n]') In [8]: message Out[8]: 'При выполнении команды "{}" возникла такая ошибка "{}".\nИсключить эту команду из списка? [y/n]'
Список (List)
Список в Python это:
- Последовательность элементов, разделенных между собой запятой и заключенных в квадратные скобки
- Изменяемый упорядоченный тип данных
Примеры списков:
In [1]: list1 = [10,20,30,77] In [2]: list2 = ['one', 'dog', 'seven'] In [3]: list3 = [1, 20, 4.0, 'word']
Создание списка с помощью литерала:
vlans = [10, 20, 30, 50]
Создание списка с помощью функции list():
In [50]: list1 = list('router') In [51]: print (list1) ['r', 'o', 'u', 't', 'e', 'r']
Так как список - это упорядоченный тип данных, то, как и в строках, в списках можно обращаться к элементу по номеру, делать срезы:
In [52]: list3 = [1, 20, 4.0, 'word'] In [53]: list3[1] Out[53]: 20 In [54]: list3[1::] Out[54]: [20, 4.0, 'word'] In [55]: list3[-1] Out[55]: 'word' In [56]: list3[::-1] Out[56]: ['word', 4.0, 20, 1]
Перевернуть список наоборот можно и с помощью метода reverse():
In [63]: vlans = ['10', '15', '20', '30', '100-200'] In [64]: vlans.reverse() In [65]: vlans Out[65]: ['100-200', '30', '20', '15', '10']
Так как списки изменяемые, элементы списка можно менять:
In [66]: list3 Out[66]: [1, 20, 4.0, 'word'] In [67]: list3[0] = 'test' In [68]: list3 Out[68]: ['test', 20, 4.0, 'word']
Можно создавать и список списков. И, как и в обычном списке, можно обращаться к элементам во вложенных списках:
In [69]: interfaces = [['FastEthernet0/0', '15.0.15.1', 'YES', 'manual', 'up', 'up'], ...: ['FastEthernet0/1', '10.0.1.1', 'YES', 'manual', 'up', 'up'], ...: ['FastEthernet0/2', '10.0.2.1', 'YES', 'manual', 'up', 'down']] In [70]: interfaces[0][0] Out[70]: 'FastEthernet0/0' In [71]: interfaces[2][0] Out[71]: 'FastEthernet0/2' In [72]: interfaces[2][1] Out[72]: '10.0.2.1'
Функция len возвращает количество элементов в списке:
In [73]: items = [1, 2, 3] In [74]: len(items) Out[74]: 3
А функция sorted сортирует элементы списка по возрастанию и возвращает новый список с отсортированными элементами:
In [75]: names = ['John', 'Michael', 'Antony'] In [76]: sorted(names) Out[76]: ['Antony', 'John', 'Michael']
Полезные методы для работы со списками
Список - это изменяемый тип данных, поэтому очень важно обращать внимание на то, что большинство методов для работы со списками меняют список на месте, при этом ничего не возвращая.
join
Метод join собирает список строк в одну строку с разделителем, который указан перед join:
In [16]: vlans = ['10', '20', '30'] In [17]: ','.join(vlans) Out[17]: '10,20,30'
append
Метод append добавляет в конец списка указанный элемент:
In [18]: vlans = ['10', '20', '30', '100-200'] In [19]: vlans.append('300') In [20]: vlans Out[20]: ['10', '20', '30', '100-200', '300']
extend
Если нужно объединить два списка, то можно использовать два способа: метод extend и операцию сложения.
У этих способов есть важное отличие - extend меняет список, к которому применен метод, а суммирование возвращает новый список, который состоит из двух.
Метод extend:
In [21]: vlans = ['10', '20', '30', '100-200'] In [22]: vlans2 = ['300', '400', '500'] In [23]: vlans.extend(vlans2) In [24]: vlans Out[24]: ['10', '20', '30', '100-200', '300', '400', '500']
Суммирование списков:
In [27]: vlans = ['10', '20', '30', '100-200'] In [28]: vlans2 = ['300', '400', '500'] In [29]: vlans + vlans2 Out[29]: ['10', '20', '30', '100-200', '300', '400', '500']
результат суммирования можно присвоить в переменную.
pop
Метод pop удаляет элемент, который соответствует указанному номеру. Но, что важно, при этом метод возвращает этот элемент:
In [28]: vlans = ['10', '20', '30', '100-200'] In [29]: vlans.pop(-1) Out[29]: '100-200' In [30]: vlans Out[30]: ['10', '20', '30']
Без указания номера удаляется последний элемент списка.
remove
Метод remove удаляет указанный элемент.
remove() не возвращает удаленный элемент:
In [31]: vlans = ['10', '20', '30', '100-200'] In [32]: vlans.remove('20') In [33]: vlans Out[33]: ['10', '30', '100-200']
В методе remove надо указывать сам элемент, который надо удалить, а не его номер в списке. Если указать номер элемента, возникнет ошибка
index
Метод index используется для того, чтобы проверить, под каким номером в списке хранится элемент:
In [35]: vlans = ['10', '20', '30', '100-200'] In [36]: vlans.index('30') Out[36]: 2
insert
Метод insert позволяет вставить элемент на определенное место в списке:
In [37]: vlans = ['10', '20', '30', '100-200'] In [38]: vlans.insert(1, '15') In [39]: vlans Out[39]: ['10', '15', '20', '30', '100-200']
sort
Метод sort сортирует список на месте:
In [40]: vlans = [1, 50, 10, 15] In [41]: vlans.sort() In [42]: vlans Out[42]: [1, 10, 15, 50]
Словарь (Dictionary)
Словари - это изменяемый упорядоченный тип данных:
- данные в словаре - это пары ключ: значение
- доступ к значениям осуществляется по ключу, а не по номеру, как в списках
- данные в словаре упорядочены по порядку добавления элементов
- так как словари изменяемы, то элементы словаря можно менять, добавлять, удалять
- ключ должен быть объектом неизменяемого типа: число, строка, кортеж
- значение может быть данными любого типа
Пример словаря:
london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'}
Можно записывать и так:
london = { 'id': 1, 'name': 'London', 'it_vlan': 320, 'user_vlan': 1010, 'mngmt_vlan': 99, 'to_name': None, 'to_id': None, 'port': 'G1/0/11' }
Для того, чтобы получить значение из словаря, надо обратиться по ключу, таким же образом, как это было в списках, только вместо номера будет использоваться ключ:
In [80]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [81]: print(london) {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'}
В словаре в качестве значения можно использовать словарь:
london_co = { 'r1': { 'hostname': 'london_r1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.1' }, 'r2': { 'hostname': 'london_r2', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '4451', 'ios': '15.4', 'ip': '10.255.0.2' }, 'sw1': { 'hostname': 'london_sw1', 'location': '21 New Globe Walk', 'vendor': 'Cisco', 'model': '3850', 'ios': '3.6.XE', 'ip': '10.255.0.101' } }
Получить значения из вложенного словаря можно так:
In [83]: london_co['r1']['ios'] Out[83]: '15.4'
Функция sorted сортирует ключи словаря по возрастанию и возвращает новый список с отсортированными ключами:
In [84]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [85]: sorted(london) Out[85]: ['location', 'name', 'vendor']
Полезные методы для работы со словарями
clear
Метод clear позволяет очистить словарь:
In [1]: london = {'name': 'London1', 'location': 'London Str'} In [2]: london.clear() In [3]: london Out[3]: {}
copy
Метод copy позволяет создать полную копию словаря.
Если указать, что один словарь равен другому:
In [4]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [5]: london2 = london In [6]: id(london) Out[6]: 25489072 In [7]: id(london2) Out[7]: 25489072 In [8]: london['vendor'] = 'Juniper' In [9]: london2['vendor'] Out[9]: 'Juniper'
В этом случае london2 это еще одно имя, которое ссылается на словарь. И при изменениях словаря london меняется и словарь london2, так как это ссылки на один и тот же объект.
Поэтому, если нужно сделать копию словаря, надо использовать метод copy():
In [10]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [11]: london2 = london.copy() In [12]: id(london) Out[12]: 25524512 In [13]: id(london2) Out[13]: 25563296 In [14]: london['vendor'] = 'Juniper' In [15]: london2['vendor'] Out[15]: 'Cisco'
get
Если при обращении к словарю указывается ключ, которого нет в словаре, возникает ошибка:
In [16]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [17]: london['ios'] --------------------------------------------------------------------------- KeyError Traceback (most recent call last)in () ----> 1 london['ios'] KeyError: 'ios'
Метод get запрашивает ключ, и если его нет, вместо ошибки возвращает None.
In [18]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [19]: print(london.get('ios')) None
Метод get() позволяет также указывать другое значение вместо None:
In [20]: print(london.get('ios', 'Ooops')) Ooops
setdefault
Метод setdefault ищет ключ, и если его нет, вместо ошибки создает ключ со значением None.
In [21]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [22]: ios = london.setdefault('ios') In [23]: print(ios) None In [24]: london Out[24]: {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco', 'ios': None}
Если ключ есть, setdefault возвращает значение, которое ему соответствует:
In [25]: london.setdefault('name') Out[25]: 'London1'
Второй аргумент позволяет указать, какое значение должно соответствовать ключу:
In [26]: model = london.setdefault('model', 'Cisco3580') In [27]: print(model) Cisco3580 In [28]: london Out[28]: {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco', 'ios': None, 'model': 'Cisco3580'}
keys, values, items
Методы keys, values, items:
In [24]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [25]: london.keys() Out[25]: dict_keys(['name', 'location', 'vendor']) In [26]: london.values() Out[26]: dict_values(['London1', 'London Str', 'Cisco']) In [27]: london.items() Out[27]: dict_items([('name', 'London1'), ('location', 'London Str'), ('vendor', 'Cisco')])
Все три метода возвращают специальные объекты view, которые отображают ключи, значения и пары ключ-значение словаря соответственно.
Очень важная особенность view заключается в том, что они меняются вместе с изменением словаря. И фактически они лишь дают способ посмотреть на соответствующие объекты, но не создают их копию.
На примере метода keys:
In [28]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [29]: keys = london.keys() In [30]: print(keys) dict_keys(['name', 'location', 'vendor'])
Сейчас переменной keys соответствует view dict_keys, в котором три ключа: name, location и vendor.
Если добавить в словарь еще одну пару ключ-значение, объект keys тоже поменяется:
In [31]: london['ip'] = '10.1.1.1' In [32]: keys Out[32]: dict_keys(['name', 'location', 'vendor', 'ip'])
Если нужно получить обычный список ключей, который не будет меняться с изменениями словаря, достаточно конвертировать view в список:
In [33]: list_keys = list(london.keys()) In [34]: list_keys Out[34]: ['name', 'location', 'vendor', 'ip']
del
Удалить ключ и значение:
In [35]: london = {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco'} In [36]: del london['name'] In [37]: london Out[37]: {'location': 'London Str', 'vendor': 'Cisco'}
update
Метод update позволяет добавлять в словарь содержимое другого словаря:
In [38]: r1 = {'name': 'London1', 'location': 'London Str'} In [39]: r1.update({'vendor': 'Cisco', 'ios':'15.2'}) In [40]: r1 Out[40]: {'name': 'London1', 'location': 'London Str', 'vendor': 'Cisco', 'ios': '15.2'}
Аналогичным образом можно обновить значения:
In [41]: r1.update({'name': 'london-r1', 'ios':'15.4'}) In [42]: r1 Out[42]: {'name': 'london-r1', 'location': 'London Str', 'vendor': 'Cisco', 'ios': '15.4'}
Кортеж (Tuple)
Кортеж в Python это:
- последовательность элементов, которые разделены между собой запятой и заключены в скобки
- неизменяемый упорядоченный тип данных
Кортеж - это список, который нельзя изменить. То есть, в кортеже есть только права на чтение. Это может быть защитой от случайных изменений.
Кортеж из одного элемента (обратите внимание на запятую):
In [87]: tuple2 = ('password',) In [88]: tuple2 Out[88]: ('password',)
Кортеж из списка:
In [89]: list_keys = ['hostname', 'location', 'vendor', 'model', 'ios', 'ip'] In [90]: tuple_keys = tuple(list_keys) In [91]: tuple_keys Out[91]: ('hostname', 'location', 'vendor', 'model', 'ios', 'ip')
К объектам в кортеже можно обращаться, как и к объектам списка, по порядковому номеру:
In [93]: tuple_keys[0] Out[93]: 'hostname'
Но так как кортеж неизменяем, присвоить новое значение нельзя.
Функция sorted сортирует элементы кортежа по возрастанию и возвращает новый список с отсортированными элементами:
In [94]: tuple_keys Out[94]: ('hostname', 'location', 'vendor', 'model', 'ios', 'ip') In [95]: sorted(tuple_keys) Out[95]: ['hostname', 'ios', 'ip', 'location', 'model', 'vendor']
Множество (Set)
Множество - это изменяемый неупорядоченный тип данных. В множестве всегда содержатся только уникальные элементы.
Множество в Python - это последовательность элементов, которые разделены между собой запятой и заключены в фигурные скобки.
С помощью множества можно легко убрать повторяющиеся элементы:
In [1]: vlans = [10, 20, 30, 40, 100, 10] In [2]: set(vlans) Out[2]: {10, 20, 30, 40, 100} In [3]: set1 = set(vlans) In [4]: print(set1) {100, 40, 10, 20, 30}
Булевы значения
Булевы значения в Python это две константы True и False.
В Python истинными и ложными значениями считаются не только True и False.
- истинное значение:
- любое ненулевое число
- любая непустая строка
- любой непустой объект - ложное значение:
- 0
- None
- пустая строка
- пустой объект
Для проверки булевого значения объекта, можно воспользоваться bool:
In [1]: vlans = [10, 20, 30, 40, 100, 10] In [2]: set(vlans) Out[2]: {10, 20, 30, 40, 100} In [3]: set1 = set(vlans) In [4]: print(set1) {100, 40, 10, 20, 30} In [5]: items = [1, 2, 3] In [6]: empty_list = [] In [7]: bool(empty_list) Out[7]: False In [8]: bool(items) Out[8]: True In [9]: bool(0) Out[9]: False In [10]: bool(1) Out[10]: True
Преобразование типов
В Python есть несколько полезных встроенных функций, которые позволяют преобразовать данные из одного типа в другой.
- int
int преобразует строку в int:In [11]: int("10") Out[11]: 10
С помощью функции int можно преобразовать и число в двоичной записи в десятичную (двоичная запись должна быть в виде строки)
In [12]: int("11111111", 2) Out[12]: 255
- bin
Преобразовать десятичное число в двоичный формат можно с помощью bin:
In [13]: bin(10)
Out[13]: '0b1010'In [14]: bin(255)
Out[14]: '0b11111111' - hex
Аналогичная функция есть и для преобразования в шестнадцатеричный формат:In [15]: hex(10) Out[15]: '0xa'
- list
Функция list преобразует аргумент в список:In [16]: list("string") Out[16]: ['s', 't', 'r', 'i', 'n', 'g'] In [17]: list((1, 2, 3, 4)) Out[17]: [1, 2, 3, 4]
- set
Функция set преобразует аргумент в множество:In [20]: set([1, 2, 3, 3, 4, 4, 4, 4]) Out[20]: {1, 2, 3, 4} In [21]: set((1, 2, 3, 3, 4, 4, 4, 4)) Out[21]: {1, 2, 3, 4} In [22]: set("string string") Out[22]: {' ', 'g', 'i', 'n', 'r', 's', 't'}
- tuple
In [23]: tuple([1, 2, 3, 4]) Out[23]: (1, 2, 3, 4) In [24]: tuple({1, 2, 3, 4}) Out[24]: (1, 2, 3, 4) In [25]: tuple("string") Out[25]: ('s', 't', 'r', 'i', 'n', 'g')
- str
Функция str преобразует аргумент в строку:In [26]: str(10) Out[26]: '10'
Проверка типов
При преобразовании типов данных могут возникнуть ошибки такого рода:
In [28]: int('a') --------------------------------------------------------------------------- ValueError Traceback (most recent call last)in ----> 1 int('a') ValueError: invalid literal for int() with base 10: 'a'
Чтобы избежать ошибок, было бы хорошо иметь возможность проверить, с чем мы работаем.
- isdigit
чтобы проверить, состоит ли строка из одних цифр, можно использовать метод isdigitIn [29]: "a".isdigit() Out[29]: False In [30]: "10".isdigit() Out[30]: True
- isalpha
Метод isalpha позволяет проверить, состоит ли строка из одних букв:In [31]: "a".isalpha() Out[31]: True In [32]: "a100".isalpha() Out[32]: False
- isalnum
Метод isalnum позволяет проверить, состоит ли строка из букв или цифр:In [33]: "a".isalnum() Out[33]: True In [34]: "a10".isalnum() Out[34]: True
- type
Иногда, в зависимости от результата, библиотека или функция может выводить разные типы объектов. Например, если объект один, возвращается строка, если несколько, то возвращается кортеж.Нам же надо построить ход программы по-разному, в зависимости от того, была ли возвращена строка или кортеж.
В этом может помочь функция type:
In [35]: type("string") Out[35]: str In [36]: type("10") Out[36]: str In [37]: type(10) Out[37]: int In [38]: type((1,2,3)) Out[38]: tuple In [39]: type((1,2,3)) == tuple Out[39]: True
Вызов методов цепочкой
Часто с данными надо выполнить несколько операций, например:
In [40]: line = "switchport trunk allowed vlan 10,20,30" In [41]: words = line.split() In [42]: words Out[42]: ['switchport', 'trunk', 'allowed', 'vlan', '10,20,30'] In [43]: vlans_str = words[-1] In [44]: vlans_str Out[44]: '10,20,30' In [45]: vlans = vlans_str.split(",") In [46]: vlans Out[46]: ['10', '20', '30']
Или в скрипте:
line = "switchport trunk allowed vlan 10,20,30" words = line.split() vlans_str = words[-1] vlans = vlans_str.split(",") print(vlans)
Однако в Python часто встречаются выражения, в которых действия или методы применяются один за другим в одном выражении. Например, предыдущий код можно записать так:
line = "switchport trunk allowed vlan 10,20,30" vlans = line.split()[-1].split(",") print(vlans)
Главный нюанс при написании таких цепочек предыдущий метод/действие должен возвращать то, что ждет следующий метод/дествие. И обязательно чтобы что-то возвращалось, иначе будет ошибка.
Основы сортировки данных
При сортировке данных типа списка списков или списка кортежей, sorted сортирует по первому элементу вложенных списков (кортежей), а если первый элемент одинаковый, по второму:
In [47]: data = [[1, 100, 1000], [2, 2, 2], [1, 2, 3], [4, 100, 3]] In [48]: sorted(data) Out[48]: [[1, 2, 3], [1, 100, 1000], [2, 2, 2], [4, 100, 3]]
Если сортировка делается для списка чисел, которые записаны как строки, сортировка будет лексикографической, не натуральной и порядок будет таким:
In [51]: vlans = ['1', '30', '11', '3', '10', '20', '30', '100'] In [52]: sorted(vlans) Out[52]: ['1', '10', '100', '11', '20', '3', '30', '30']
Чтобы сортировка была «правильной» надо преобразовать вланы в числа.
Задания
-
Используя подготовленную строку nat, получить новую строку, в которой в имени интерфейса вместо FastEthernet написано GigabitEthernet. Полученную новую строку вывести на стандартный поток вывода (stdout) с помощью print.
nat = "ip nat inside source list ACL interface FastEthernet0/1 overload"Решение
line = "ip nat inside source list ACL interface FastEthernet0/1 overload" words = line.split() words[7] = 'GigabitEthernet' line2 = words[0] + ' ' + words[1] + ' ' + words[2] + ' ' + words[3] + ' ' + words[4] + ' ' + words[5] + ' ' + words[6] + ' ' + words[7] + ' ' + words[8] print (line2)
-
Преобразовать строку в переменной mac из формата XXXX:XXXX:XXXX в формат XXXX.XXXX.XXXX Полученную новую строку вывести на стандартный поток вывода (stdout) с помощью print.
Решение
line = "XXXX:XXXX:XXXX" words = line.split(':') line2 = words[0] + '.' + words[1] + '.' + words[2] print (line2)
-
Получить из строки config такой список VLANов:
['1', '3', '10', '20', '30', '100']
Записать итоговый список в переменную result. (именно эта переменная будет проверяться в тесте)Полученный список result вывести на стандартный поток вывода (stdout) с помощью print. Тут очень важный момент, что надо получить именно список (тип данных), а не, например, строку, которая похожа на показанный список.
config = "switchport trunk allowed vlan 1,3,10,20,30,100"Решение
config = "switchport trunk allowed vlan 1,3,10,20,30,100" words = config.split() vlans_str = words[-1] result = vlans_str.split(",") print(result)
-
Список vlans это список VLANов, собранных со всех устройств сети, поэтому в списке есть повторяющиеся номера VLAN.
Из списка vlans нужно получить новый список уникальных номеров VLANов, отсортированный по возрастанию номеров. Для получения итогового списка нельзя удалять конкретные vlanы вручную.
Записать итоговый список уникальных номеров VLANов в переменную result. (именно эта переменная будет проверяться в тесте)
Полученный список result вывести на стандартный поток вывода (stdout) с помощью print.
vlans = [10, 20, 30, 1, 2, 100, 10, 30, 3, 4, 10]
Решение
vlans = [10, 20, 30, 1, 2, 100, 10, 30, 3, 4, 10] vlans2 = set(vlans) result = list(vlans2) print(result)
-
Из строк command1 и command2 получить список VLANов, которые есть и в команде command1 и в команде command2 (пересечение).
В данном случае, результатом должен быть такой список: ['1', '3', '8']
Записать итоговый список в переменную result. (именно эта переменная будет проверяться в тесте)
Полученный список result вывести на стандартный поток вывода (stdout) с помощью print.
command1 = "switchport trunk allowed vlan 1,2,3,5,8"
command2 = "switchport trunk allowed vlan 1,3,8,9"Решение
command1 = "switchport trunk allowed vlan 1,2,3,5,8" command2 = "switchport trunk allowed vlan 1,3,8,9" words1 = command1.split() words2 = command2.split() vlans_str1 = words1[-1] vlans_str2 = words2[-1] vlans1 = vlans_str1.split(",") vlans2 = vlans_str2.split(",") result = list(set(vlans1) & set(vlans2)) print(result)
-
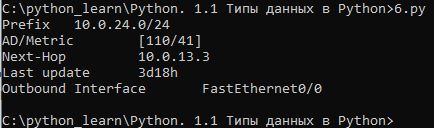
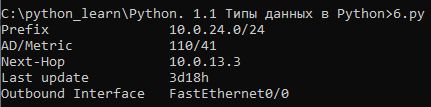
Обработать строку ospf_route и вывести информацию на стандартный поток вывода в виде:
Prefix 10.0.24.0/24
AD/Metric 110/41
Next-Hop 10.0.13.3
Last update 3d18h
Outbound Interface FastEthernet0/0ospf_route = " 10.0.24.0/24 [110/41] via 10.0.13.3, 3d18h, FastEthernet0/0"
Решение без форматирования
ospf_route = " 10.0.24.0/24 [110/41] via 10.0.13.3, 3d18h, FastEthernet0/0" words = ospf_route.split() print ('Prefix\t',words[0]) print ('AD/Metric\t',words[1]) print ('Next-Hop\t',words[3][:-1]) print ('Last update\t',words[4][:-1]) print ('Outbound Interface\t',words[5])
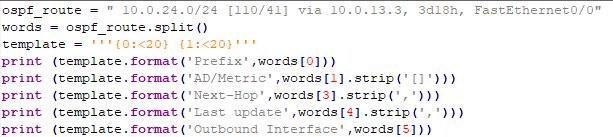
Решение с использованием форматирования, а также метода strip:
-
Преобразовать MAC-адрес в строке mac в двоичную строку такого вида: „101010101010101010111011101110111100110011001100“
Полученную новую строку вывести на стандартный поток вывода (stdout) с помощью print.
mac = "AAAA:BBBB:CCCC"Решение
mac = "D45D:6401:01BC" mac_hex = mac.split(":") mac_string = mac_hex[0] + mac_hex[1] +mac_hex[2] int = int(mac_string, 16) result = bin(int)

-
Преобразовать IP-адрес в переменной ip в двоичный формат и вывести на стандартный поток вывода вывод столбцами, таким образом:
первой строкой должны идти десятичные значения байтов
второй строкой двоичные значения
Вывод должен быть упорядочен также, как в примере:столбцами
ширина столбца 10 символов (в двоичном формате надо добавить два пробела между столбцами для разделения октетов между собой)
Пример вывода для адреса 10.1.1.1:10 1 1 1 00001010 00000001 00000001 00000001
ip = "192.168.3.1"
Решение без форматирования:
ip = "192.168.3.1" ip_split = ip.split(".") print(ip_split[0],' '*10,ip_split[1],' '*10,ip_split[2],' '*10,ip_split[3]) print(bin(int(ip_split[0])),' '*2,bin(int(ip_split[1])),' '*2,bin(int(ip_split[2])),' '*2,bin(int(ip_split[3])))

Решение с форматированием:


Задания
- Задание 6.1
Список mac содержит MAC-адреса в формате XXXX:XXXX:XXXX. Однако, в оборудовании cisco MAC-адреса используются в формате XXXX.XXXX.XXXX.Написать код, который преобразует MAC-адреса в формат cisco и добавляет их в новый список result. Полученный список result вывести на стандартный поток вывода (stdout) с помощью print.
Ограничение: Все задания надо выполнять используя только пройденные темы.
mac = ["aabb:cc80:7000", "aabb:dd80:7340", "aabb:ee80:7000", "aabb:ff80:7000"]
Решение
mac = ["aabb:cc80:7000", "aabb:dd80:7340", "aabb:ee80:7000", "aabb:ff80:7000"] result = [] for line in mac: words = line.split(':') line2 = words[0] + '.' + words[1] + '.' + words[2] result.append(line2) print (result)
Более правильное решение
mac = ["aabb:cc80:7000", "aabb:dd80:7340", "aabb:ee80:7000", "aabb:ff80:7000"] result = [] for line in mac: result.append(line.replace(":", ".")) print(result)
Работа с Eltex

UserGate с нуля

Security

- Cisco ISE с нуля: краткая теория (Часть 1)
- Cisco ISE с нуля: Установка ISE (Часть 2)
- Cisco ISE с нуля: Краткая теория о Authentication Policies и Authorization Policies (Часть 3)
- Cisco ISE с нуля: Wireless Authentication (Часть 4)
- Cisco ISE с нуля: Настройка Web Authentication, Guest WebAuth (Часть 5)
- Cisco ISE с нуля: настройка TACACS (часть 6)
Работа с ISE 3.2
Технологии VPN
- DMVPN и EIGRP
- DMVPN и резервный ISP
- Автопереключение между двумя провайдерами
- Подключение региональных офисов с серыми адресами по VPN
- Web VPN: подключение отовсюду
- Установка AnyConnect SSLVPN на IOS Router
- Работа с ASA Anyconnect SSL VPN HUB
- ASA и Wildcard certificate
- Настройка 3G/4G на Cisco ISR 1100 LTE 4g/3g Cellular
VoIP Voice Monitoring
VoIP Troubleshooting

- Обзор Cisco Unified Comunications System Troubleshooting
- Архивирование и восстановление Cisco Call Manager CUCM
- Поиск проблем с маршрутизацией CUCM с использованием traces
- Логирование и трекинг (trace) звонков в CUCM
- Работа с RTMT
- Полезное в RTMT
- Настройка учета звонков в CUCM
- CUCM Dialed Number Analyzer
- Полезные команды UCCX
CUCM и Факсы
Архивация и восстановление CUCM

Работа с медиа-ресурсами


SIP и Call Manager
- Часть 1 Теория
- Часть 2 Настройка SIP gateway
- Часть 3 Подключение CUCM к SIP ITSP
- Часть 6 Подключение к SIP-провайдеру
- Подключение CUCM к двум и более SIP операторам с авторизацией (sipnet + telphin). CUBE Multiple Registrars
- Подключение CUCM к SIP оператору с авторизацией по нескольким учеткам одновременно. (domru, sipnet, telphin, beeline) CUBE Multiple Registrars
- Cisco CUBE и Tenants
- Работа со "сложными" провайдерами SIP IP телефонии
Работа со стендом
- Настройка Cisco Unified Comunications с нуля. Практика01: Установка CUCM
- Настройка Cisco Unified Comunications с нуля. Практика02: Установка CUC
- Настройка Cisco Unified Comunications с нуля. Практика03: Установка CUP
- Настройка Cisco Unified Comunications с нуля. Практика04: Установка UCCX
- Настройка Cisco Unified Comunications с нуля. Практика05: Установка шлюза MGCP FXO
- Настройка Cisco Unified Comunications с нуля. Практика06: Переход в другой домен AD
- Настройка Cisco Unified Comunications с нуля. Практика07: Полное восстановление кластера CUCM 8.6 из архива
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_01: Описание
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_02: Установка CUCM
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_03: Установка UCCX
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_04: Установка Mediasense

Добавить комментарий