
Главное меню
Навигация
Настраиваем с нуля
Цикл статей Настройка Call Manager Express CUCME с нуля:
Цикл статей Настройка Call Manager CUCM с нуля:
Comunications Apps с нуля
UCCX
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 1
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 2
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 3
- Настройка UCCX 10.x, 11.x + Cisco Finesse desktop
- Установка скрипта для записи UCCX Prompts
CUC
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 1
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 2
CUP
- Настройка Cisco Unified Presence (CUP) с нуля. Теория
- Настройка Cisco Unified Presence (CUP) с нуля. Практика: Начальная установка
MediaSense
Настройка комплекта Cisco CUCM Business Edition 6000
- Настройка комплекта BE6000: Введение
- Настройка комплекта BE6000: Установка CUCM 11
- Настройка комплекта BE6000: Начальная установка CUC 11
- Настройка комплекта BE6000: Немного теории CUC 11
- Настройка комплекта BE6000: Настраиваем своего автосекретаря (IVR) в CUC 11
- Настройка комплекта BE6000: правильная Архивация CUCM 11.5
- Настройка комплекта BE6000: Восстановление CUCM 11.5 из архива
- Настройка комплекта BE6000: устанавливаем лицензии для телефонов CUCM 11.5
- Настройка комплекта BE6000: настройка конференции ad hoc CUCM 11.5
- Настройка комплекта BE6000: настройка конференции meet-me CUCM 11.5
- Настройка комплекта BE6000: настройка мониторинга комплекса CUCM 11.5
CUCM в крупном предприятии
- SRST. Теория (часть 1)
- SRST: Практика (Часть 2)
- Диалплан (dialplan) в крупной организации
- Cisco Device Mobility. Теория
- Cisco Device Mobility. Настройка
- Cisco Extension Mobility. Теория
- Cisco Extension Mobility. Настройка
- Call Control Discovery
- Настройка Multicast MOH Server на маршрутизаторах филиалов
- Cisco H.323 Gatekeeper. Теория
- Cisco H.323 Gatekeeper. Настройка и Практика
- Cisco H.323 Gatekeeper и Call Admission Control
- Практика подключения H.323 и SIP с использованием CUBE
- CUCM и LDAP Integration
DTMF и его настройка
Вы здесь
Python. 1.5 Примеры использования основ
Форматирование строк с помощью f-строк
F-строки позволяют не только подставлять какие-то значения в шаблон, но и позволяют выполнять вызовы функций, методов и т.п.
Во многих ситуациях f-строки удобней и проще использовать, чем format, кроме того, f-строки работают быстрее, чем format и другие методы форматирования строк.
Синтаксис f-строк
F-строки - это литерал строки с буквой f перед ним. Внутри f-строки в паре фигурных скобок указываются имена переменных, которые надо подставить:
In [1]: ip = '10.1.1.1' In [2]: mask = 24 In [3]: f"IP: {ip}, mask: {mask}" Out[3]: 'IP: 10.1.1.1, mask: 24'
Аналогичный результат с format можно получить так:
"IP: {ip}, mask: {mask}".format(ip=ip, mask=mask)
Очень важное отличие f-строк от format: f-строки это выражение, которое выполняется, а не просто строка. То есть, в случае с ipython, как только мы написали выражение и нажали Enter, оно выполнилось и вместо выражений {ip} и {mask} подставились значения переменных.
Поэтому, например, нельзя сначала написать шаблон, а затем определить переменные, которые используются в шаблоне:
In [1]: f"IP: {ip}, mask: {mask}" --------------------------------------------------------------------------- NameError Traceback (most recent call last)in () ----> 1 f"IP: {ip}, mask: {mask}" NameError: name 'ip' is not defined
Кроме подстановки значений переменных, в фигурных скобках можно писать выражения:
In [1]: octets = ['10', '1', '1', '1'] In [2]: mask = 24 In [3]: f"IP: {'.'.join(octets)}, mask: {mask}" Out[3]: 'IP: 10.1.1.1, mask: 24'
После двоеточия в f-строках можно указывать те же значения, что и при использовании format: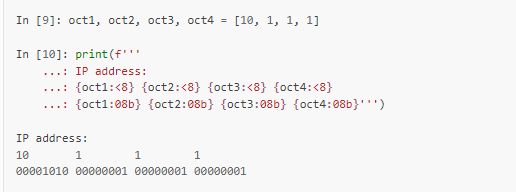
Особенности использования f-строк
При использовании f-строк нельзя сначала создать шаблон, а затем его использовать, как при использовании format.
F-строка сразу выполняется и в нее подставляются значения переменных, которые должны быть определены ранее:
In [7]: ip = '10.1.1.1' In [8]: mask = 24 In [9]: print(f"IP: {ip}, mask: {mask}") IP: 10.1.1.1, mask: 24
Если необходимо подставить другие значения, надо создать новые переменные (с теми же именами) и снова написать f-строку:
In [11]: ip = '10.2.2.2' In [12]: mask = 24 In [13]: print(f"IP: {ip}, mask: {mask}") IP: 10.2.2.2, mask: 24
При использовании f-строк в циклах, f-строку надо писать в теле цикла, чтобы она «подхватывала» новые значения переменных на каждой итерации:
In [1]: ip_list = ['10.1.1.1/24', '10.2.2.2/24', '10.3.3.3/24'] In [2]: for ip_address in ip_list: ...: ip, mask = ip_address.split('/') ...: print(f"IP: {ip}, mask: {mask}") ...: IP: 10.1.1.1, mask: 24 IP: 10.2.2.2, mask: 24 IP: 10.3.3.3, mask: 24
Примеры использования f-строк
Базовая подстановка переменных:
In [1]: intf_type = 'Gi' In [2]: intf_name = '0/3' In [3]: f'interface {intf_type}/{intf_name}' Out[3]: 'interface Gi0/3'
Выравнивание столбцами:
In [6]: topology = [['sw1', 'Gi0/1', 'r1', 'Gi0/2'], ...: ['sw1', 'Gi0/2', 'r2', 'Gi0/1'], ...: ['sw1', 'Gi0/3', 'r3', 'Gi0/0'], ...: ['sw1', 'Gi0/5', 'sw4', 'Gi0/2']] ...: In [7]: for connection in topology: ...: l_device, l_port, r_device, r_port = connection ...: print(f'{l_device:10} {l_port:7} {r_device:10} {r_port:7}') ...: sw1 Gi0/1 r1 Gi0/2 sw1 Gi0/2 r2 Gi0/1 sw1 Gi0/3 r3 Gi0/0 sw1 Gi0/5 sw4 Gi0/2
Ширина столбцов может быть указана через переменную:
In [6]: topology = [['sw1', 'Gi0/1', 'r1', 'Gi0/2'], ...: ['sw1', 'Gi0/2', 'r2', 'Gi0/1'], ...: ['sw1', 'Gi0/3', 'r3', 'Gi0/0'], ...: ['sw1', 'Gi0/5', 'sw4', 'Gi0/2']] ...: In [7]: width = 10 In [8]: for connection in topology: ...: l_device, l_port, r_device, r_port = connection ...: print(f'{l_device:{width}} {l_port:{width}} {r_device:{width}} {r_port:{width}}') ...: sw1 Gi0/1 r1 Gi0/2 sw1 Gi0/2 r2 Gi0/1 sw1 Gi0/3 r3 Gi0/0 sw1 Gi0/5 sw4 Gi0/2
Работа со словарями
In [1]: session_stats = {'done': 10, 'todo': 5} In [2]: if session_stats['todo']: ...: print(f"Pomodoros done: {session_stats['done']}, TODO: {session_stats['todo']}") ...: else: ...: print(f"Good job! All {session_stats['done']} pomodoros done!") ...: Pomodoros done: 10, TODO: 5
Вызов функции len внутри f-строки:
In [2]: topology = [['sw1', 'Gi0/1', 'r1', 'Gi0/2'], ...: ['sw1', 'Gi0/2', 'r2', 'Gi0/1'], ...: ['sw1', 'Gi0/3', 'r3', 'Gi0/0'], ...: ['sw1', 'Gi0/5', 'sw4', 'Gi0/2']] ...: In [3]: print(f'Количество подключений в топологии: {len(topology)}') Количество подключений в топологии: 4
Вызов метода upper внутри f-строки:
In [1]: name = 'python' In [2]: print(f'Zen of {name.upper()}') Zen of PYTHON
Конвертация чисел в двоичный формат:
In [7]: ip = '10.1.1.1' In [8]: oct1, oct2, oct3, oct4 = ip.split('.') In [9]: print(f'{int(oct1):08b} {int(oct2):08b} {int(oct3):08b} {int(oct4):08b}') 00001010 00000001 00000001 00000001
Что использовать format или f-строки
Во многих случаях f-строки удобней использовать, так как шаблон выглядит понятней и компактней. Однако бывают случаи, когда метод format удобней. Например:
In [6]: ip = [10, 1, 1, 1] In [7]: oct1, oct2, oct3, oct4 = ip ...: print(f'{oct1:08b} {oct2:08b} {oct3:08b} {oct4:08b}') ...: 00001010 00000001 00000001 00000001 In [8]: template = "{:08b} "*4 In [9]: template.format(oct1, oct2, oct3, oct4) Out[9]: '00001010 00000001 00000001 00000001
'
Еще одна ситуация, когда format, как правило, удобней использовать: необходимость использовать в скрипте один и тот же шаблон много раз. F-строка выполнится первый раз и подставит текущие значения переменных и для использования шаблона еще раз, его надо заново писать. Это значит, что в скрипте будут находится копии одной и то же строки. В то же время format позволяет создать шаблон в одном месте и потом использовать его повторно, подставляя переменные по мере необходимости.
Это можно обойти создав функцию, но создавать функцию для вывода строки по шаблону далеко не всегда оправдано. Пример создания функции:
In [1]: def show_me_ip(ip, mask): ...: return f"IP: {ip}, mask: {mask}" ...: In [2]: show_me_ip('10.1.1.1', 24) Out[2]: 'IP: 10.1.1.1, mask: 24' In [3]: show_me_ip('192.16.10.192', 28) Out[3]: 'IP: 192.16.10.192, mask: 28'
Распаковка переменных
Распаковка переменных - это специальный синтаксис, который позволяет присваивать переменным элементы итерируемого объекта.
Достаточно часто этот функционал встречается под именем tuple unpacking, но распаковка работает на любом итерируемом объекте, не только с кортежами
Пример распаковки переменных:
In [1]: interface = ['FastEthernet0/1', '10.1.1.1', 'up', 'up'] In [2]: intf, ip, status, protocol = interface In [3]: intf Out[3]: 'FastEthernet0/1' In [4]: ip Out[4]: '10.1.1.1'
Такой вариант намного удобней использовать, чем использование индексов:
In [5]: intf, ip, status, protocol = interface[0], interface[1], interface[2], interface[3]
При распаковке переменных каждый элемент списка попадает в соответствующую переменную. Важно учитывать, что переменных слева должно быть ровно столько, сколько элементов в списке.
Если переменных больше или меньше, возникнет исключение:
Замена ненужных элементов _
Часто из всех элементов итерируемого объекта нужны только некоторые. При этом синтаксис распаковки требует указать ровно столько переменных, сколько элементов в итерируемом объекте.
Если, например, из строки line надо получить только VLAN, MAC и интерфейс, надо все равно указать переменную для типа записи:
In [8]: line = '100 01bb.c580.7000 DYNAMIC Gi0/1' In [9]: vlan, mac, item_type, intf = line.split() In [10]: vlan Out[10]: '100' In [11]: intf Out[11]: 'Gi0/1'
Если тип записи не нужен в дальнейшем, можно заменить переменную item_type нижним подчеркиванием:Если тип записи не нужен в дальнейшем, можно заменить переменную item_type нижним подчеркиванием:
In [12]: vlan, mac, _, intf = line.split()
Таким образом явно указывается то, что этот элемент не нужен.
Нижнее подчеркивание можно использовать и несколько раз:
In [13]: dhcp = '00:09:BB:3D:D6:58 10.1.10.2 86250 dhcp-snooping 10 FastEthernet0/1' In [14]: mac, ip, _, _, vlan, intf = dhcp.split() In [15]: mac Out[15]: '00:09:BB:3D:D6:58' In [16]: vlan Out[16]: '10'
Использование *
Распаковка переменных поддерживает специальный синтаксис, который позволяет распаковывать несколько элементов в один. Если поставить * перед именем переменной, в нее запишутся все элементы, кроме тех, что присвоены явно.
Например, так можно получить первый элемент в переменную first, а остальные в rest:
In [18]: vlans = [10, 11, 13, 30] In [19]: first, *rest = vlans In [20]: first Out[20]: 10 In [21]: rest Out[21]: [11, 13, 30]
Если элемент всего один, распаковка все равно отработает:
In [25]: first, *rest = vlans In [26]: first Out[26]: 55 In [27]: rest Out[27]: []
Такая переменная со звездочкой в выражении распаковки может быть только одна.
Такая переменная может находиться не только в конце выражения:
In [34]: cdp = 'SW1 Eth 0/0 140 S I WS-C3750- Eth 0/1' In [35]: name, l_intf, *other, r_intf = cdp.split() In [36]: name Out[36]: 'SW1' In [37]: l_intf Out[37]: 'Eth' In [38]: r_intf Out[38]: '0/1'
Примеры распаковки
Распаковка range:
In [39]: first, *rest = range(1, 6) In [40]: first Out[40]: 1 In [41]: rest Out[41]: [2, 3, 4, 5]
Распаковка zip:
In [42]: a = [1, 2, 3, 4, 5] In [43]: b = [100, 200, 300, 400, 500] In [44]: zip(a, b) Out[44]:In [45]: list(zip(a, b)) Out[45]: [(1, 100), (2, 200), (3, 300), (4, 400), (5, 500)] In [46]: first, *rest, last = zip(a, b) In [47]: first Out[47]: (1, 100) In [48]: rest Out[48]: [(2, 200), (3, 300), (4, 400)] In [49]: last Out[49]: (5, 500)
Пример распаковки в цикле for
Пример цикла, который проходится по ключам:
In [50]: access_template = ['switchport mode access', ...: 'switchport access vlan', ...: 'spanning-tree portfast', ...: 'spanning-tree bpduguard enable'] ...: In [51]: access = {'0/12': 10, '0/14': 11, '0/16': 17} In [52]: for intf in access: ...: print(f'interface FastEthernet {intf}') ...: for command in access_template: ...: if command.endswith('access vlan'): ...: print(' {} {}'.format(command, access[intf])) ...: else: ...: print(' {}'.format(command)) ...: interface FastEthernet0/12 switchport mode access switchport access vlan 10 spanning-tree portfast spanning-tree bpduguard enable interface FastEthernet0/14 switchport mode access switchport access vlan 11 spanning-tree portfast spanning-tree bpduguard enable interface FastEthernet0/16 switchport mode access switchport access vlan 17 spanning-tree portfast spanning-tree bpduguard enable
Вместо этого можно проходиться по парам ключ-значение и сразу же распаковывать их в разные переменные:
In [53]: for intf, vlan in access.items(): ...: print(f'interface FastEthernet {intf}') ...: for command in access_template: ...: if command.endswith('access vlan'): ...: print(' {} {}'.format(command, vlan)) ...: else: ...: print(' {}'.format(command)) ...:
Пример распаковки элементов списка в цикле:
In [54]: table Out[54]: [['100', 'a1b2.ac10.7000', 'DYNAMIC', 'Gi0/1'], ['200', 'a0d4.cb20.7000', 'DYNAMIC', 'Gi0/2'], ['300', 'acb4.cd30.7000', 'DYNAMIC', 'Gi0/3'], ['100', 'a2bb.ec40.7000', 'DYNAMIC', 'Gi0/4'], ['500', 'aa4b.c550.7000', 'DYNAMIC', 'Gi0/5'], ['200', 'a1bb.1c60.7000', 'DYNAMIC', 'Gi0/6'], ['300', 'aa0b.cc70.7000', 'DYNAMIC', 'Gi0/7']] In [55]: for line in table: ...: vlan, mac, _, intf = line ...: print(vlan, mac, intf) ...: 100 a1b2.ac10.7000 Gi0/1 200 a0d4.cb20.7000 Gi0/2 300 acb4.cd30.7000 Gi0/3 100 a2bb.ec40.7000 Gi0/4 500 aa4b.c550.7000 Gi0/5 200 a1bb.1c60.7000 Gi0/6 300 aa0b.cc70.7000 Gi0/7
Но еще лучше сделать так:
In [56]: for vlan, mac, _, intf in table: ...: print(vlan, mac, intf) ...: 100 a1b2.ac10.7000 Gi0/1 200 a0d4.cb20.7000 Gi0/2 300 acb4.cd30.7000 Gi0/3 100 a2bb.ec40.7000 Gi0/4 500 aa4b.c550.7000 Gi0/5 200 a1bb.1c60.7000 Gi0/6 300 aa0b.cc70.7000 Gi0/7
List, dict, set comprehensions
Python поддерживает специальные выражения, которые позволяют компактно создавать списки, словари и множества.
На английском эти выражения называются, соответственно:
- List comprehensions
- Dict comprehensions
- Set comprehensions
К сожалению, официальный перевод на русский звучит как абстракция списков или списковое включение, что не особо помогает понять суть объекта.
В книге использовался перевод «генератор списка», что, к сожалению, тоже не самый удачный вариант, так как в Python есть отдельное понятие генератор и генераторные выражения, но он лучше отображает суть выражения.
Эти выражения не только позволяют более компактно создавать соответствующие объекты, но и создают их быстрее. И хотя поначалу они требуют определенной привычки использования и понимания, они очень часто используются.
List comprehensions (генераторы списков)
Генератор списка - это выражение вида:
In [1]: vlans = [f'vlan {num}' for num in range(10,16)] In [2]: print(vlans) ['vlan 10', 'vlan 11', 'vlan 12', 'vlan 13', 'vlan 14', 'vlan 15']
В общем случае, это выражение, которое преобразует итерируемый объект в список. То есть, последовательность элементов преобразуется и добавляется в новый список.
Выражению выше аналогичен такой цикл:
In [3]: vlans = [] In [4]: for num in range(10,16): ...: vlans.append(f'vlan {num}') ...: In [5]: print(vlans) ['vlan 10', 'vlan 11', 'vlan 12', 'vlan 13', 'vlan 14', 'vlan 15']
В list comprehensions можно использовать выражение if. Таким образом можно добавлять в список только некоторые объекты.
Например, такой цикл отбирает те элементы, которые являются числами, конвертирует их и добавляет в итоговый список only_digits:
In [6]: items = ['10', '20', 'a', '30', 'b', '40'] In [7]: only_digits = [] In [8]: for item in items: ...: if item.isdigit(): ...: only_digits.append(int(item)) ...: In [9]: print(only_digits) [10, 20, 30, 40]
Аналогичный вариант в виде list comprehensions:
In [10]: items = ['10', '20', 'a', '30', 'b', '40'] In [11]: only_digits = [int(item) for item in items if item.isdigit()] In [12]: print(only_digits) [10, 20, 30, 40]
Конечно, далеко не все циклы можно переписать как генератор списка, но когда это можно сделать, и при этом выражение не усложняется, лучше использовать генераторы списка.
С помощью генератора списка также удобно получать элементы из вложенных словарей:
In [13]: london_co = { ...: 'r1' : { ...: 'hostname': 'london_r1', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '4451', ...: 'IOS': '15.4', ...: 'IP': '10.255.0.1' ...: }, ...: 'r2' : { ...: 'hostname': 'london_r2', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '4451', ...: 'IOS': '15.4', ...: 'IP': '10.255.0.2' ...: }, ...: 'sw1' : { ...: 'hostname': 'london_sw1', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '3850', ...: 'IOS': '3.6.XE', ...: 'IP': '10.255.0.101' ...: } ...: } In [14]: [london_co[device]['IOS'] for device in london_co] Out[14]: ['15.4', '15.4', '3.6.XE'] In [15]: [london_co[device]['IP'] for device in london_co] Out[15]: ['10.255.0.1', '10.255.0.2', '10.255.0.101']
На самом деле, синтаксис генератора списка выглядит так:
[expression for item1 in iterable1 if condition1 for item2 in iterable2 if condition2 ... for itemN in iterableN if conditionN ]
Это значит, можно использовать несколько for в выражении.
Например, в списке vlans находятся несколько вложенных списков с VLAN’ами:
In [16]: vlans = [[10,21,35], [101, 115, 150], [111, 40, 50]]
Из этого списка надо сформировать один плоский список с номерами VLAN. Первый вариант — с помощью циклов for:
In [17]: result = [] In [18]: for vlan_list in vlans: ...: for vlan in vlan_list: ...: result.append(vlan) ...: In [19]: print(result) [10, 21, 35, 101, 115, 150, 111, 40, 50]
Аналогичный вариант с генератором списков:
In [20]: vlans = [[10,21,35], [101, 115, 150], [111, 40, 50]] In [21]: result = [vlan for vlan_list in vlans for vlan in vlan_list] In [22]: print(result) [10, 21, 35, 101, 115, 150, 111, 40, 50]
Можно одновременно проходиться по двум последовательностям, используя zip:
In [23]: vlans = [100, 110, 150, 200] In [24]: names = ['mngmt', 'voice', 'video', 'dmz'] In [25]: result = ['vlan {}\n name {}'.format(vlan, name) for vlan, name in zip(vlans, names)] In [26]: print('\n'.join(result)) vlan 100 name mngmt vlan 110 name voice vlan 150 name video vlan 200 name dmz
Dict comprehensions (генераторы словарей)
Генераторы словарей аналогичны генераторам списков, но они используются для создания словарей.
Например, такое выражение:
In [27]: d = {} In [28]: for num in range(1, 11): ...: d[num] = num**2 ...: In [29]: print(d) {1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
Можно заменить генератором словаря:
In [30]: d = {num: num**2 for num in range(1, 11)} In [31]: print(d) {1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
Еще один пример, в котором надо преобразовать существующий словарь и перевести все ключи в нижний регистр. Для начала, вариант решения без генератора словаря:
In [32]: r1 = {'IOS': '15.4', ...: 'IP': '10.255.0.1', ...: 'hostname': 'london_r1', ...: 'location': '21 New Globe Walk', ...: 'model': '4451', ...: 'vendor': 'Cisco'} ...: In [33]: lower_r1 = {} In [34]: for key, value in r1.items(): ...: lower_r1[key.lower()] = value ...: In [35]: lower_r1 Out[35]: {'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}
Аналогичный вариант с помощью генератора словаря:
In [36]: r1 = {'IOS': '15.4', ...: 'IP': '10.255.0.1', ...: 'hostname': 'london_r1', ...: 'location': '21 New Globe Walk', ...: 'model': '4451', ...: 'vendor': 'Cisco'} ...: In [37]: lower_r1 = {key.lower(): value for key, value in r1.items()} In [38]: lower_r1 Out[38]: {'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}
Как и list comprehensions, dict comprehensions можно делать вложенными. Попробуем аналогичным образом преобразовать ключи во вложенных словарях:
In [39]: london_co = { ...: 'r1' : { ...: 'hostname': 'london_r1', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '4451', ...: 'IOS': '15.4', ...: 'IP': '10.255.0.1' ...: }, ...: 'r2' : { ...: 'hostname': 'london_r2', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '4451', ...: 'IOS': '15.4', ...: 'IP': '10.255.0.2' ...: }, ...: 'sw1' : { ...: 'hostname': 'london_sw1', ...: 'location': '21 New Globe Walk', ...: 'vendor': 'Cisco', ...: 'model': '3850', ...: 'IOS': '3.6.XE', ...: 'IP': '10.255.0.101' ...: } ...: } In [40]: lower_london_co = {} In [41]: for device, params in london_co.items(): ...: lower_london_co[device] = {} ...: for key, value in params.items(): ...: lower_london_co[device][key.lower()] = value ...: In [42]: lower_london_co Out[42]: {'r1': {'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}, 'r2': {'hostname': 'london_r2', 'ios': '15.4', 'ip': '10.255.0.2', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}, 'sw1': {'hostname': 'london_sw1', 'ios': '3.6.XE', 'ip': '10.255.0.101', 'location': '21 New Globe Walk', 'model': '3850', 'vendor': 'Cisco'}}
Аналогичное преобразование с dict comprehensions:
In [43]: result = {device: {key.lower(): value for key, value in params.items()} for device, params in london_co.items()} In [44]: result Out[44]: {'r1': {'hostname': 'london_r1', 'ios': '15.4', 'ip': '10.255.0.1', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}, 'r2': {'hostname': 'london_r2', 'ios': '15.4', 'ip': '10.255.0.2', 'location': '21 New Globe Walk', 'model': '4451', 'vendor': 'Cisco'}, 'sw1': {'hostname': 'london_sw1', 'ios': '3.6.XE', 'ip': '10.255.0.101', 'location': '21 New Globe Walk', 'model': '3850', 'vendor': 'Cisco'}}
Set comprehensions (генераторы множеств)
Генераторы множеств в целом аналогичны генераторам списков.
Например, надо получить множество с уникальными номерами VLAN’ов:
In [45]: vlans = [10, '30', 30, 10, '56'] In [46]: unique_vlans = {int(vlan) for vlan in vlans} In [47]: unique_vlans Out[47]: {10, 30, 56}
Аналогичное решение, без использования set comprehensions:
In [48]: vlans = [10, '30', 30, 10, '56'] In [49]: unique_vlans = set() In [50]: for vlan in vlans: ...: unique_vlans.add(int(vlan)) ...: In [51]: unique_vlans Out[51]: {10, 30, 56}
Работа с Eltex

UserGate с нуля

Security

- Cisco ISE с нуля: краткая теория (Часть 1)
- Cisco ISE с нуля: Установка ISE (Часть 2)
- Cisco ISE с нуля: Краткая теория о Authentication Policies и Authorization Policies (Часть 3)
- Cisco ISE с нуля: Wireless Authentication (Часть 4)
- Cisco ISE с нуля: Настройка Web Authentication, Guest WebAuth (Часть 5)
- Cisco ISE с нуля: настройка TACACS (часть 6)
Работа с ISE 3.2
Технологии VPN
- DMVPN и EIGRP
- DMVPN и резервный ISP
- Автопереключение между двумя провайдерами
- Подключение региональных офисов с серыми адресами по VPN
- Web VPN: подключение отовсюду
- Установка AnyConnect SSLVPN на IOS Router
- Работа с ASA Anyconnect SSL VPN HUB
- ASA и Wildcard certificate
- Настройка 3G/4G на Cisco ISR 1100 LTE 4g/3g Cellular
VoIP Voice Monitoring
VoIP Troubleshooting

- Обзор Cisco Unified Comunications System Troubleshooting
- Архивирование и восстановление Cisco Call Manager CUCM
- Поиск проблем с маршрутизацией CUCM с использованием traces
- Логирование и трекинг (trace) звонков в CUCM
- Работа с RTMT
- Полезное в RTMT
- Настройка учета звонков в CUCM
- CUCM Dialed Number Analyzer
- Полезные команды UCCX
CUCM и Факсы
Архивация и восстановление CUCM

Работа с медиа-ресурсами


SIP и Call Manager
- Часть 1 Теория
- Часть 2 Настройка SIP gateway
- Часть 3 Подключение CUCM к SIP ITSP
- Часть 6 Подключение к SIP-провайдеру
- Подключение CUCM к двум и более SIP операторам с авторизацией (sipnet + telphin). CUBE Multiple Registrars
- Подключение CUCM к SIP оператору с авторизацией по нескольким учеткам одновременно. (domru, sipnet, telphin, beeline) CUBE Multiple Registrars
- Cisco CUBE и Tenants
- Работа со "сложными" провайдерами SIP IP телефонии
Работа со стендом
- Настройка Cisco Unified Comunications с нуля. Практика01: Установка CUCM
- Настройка Cisco Unified Comunications с нуля. Практика02: Установка CUC
- Настройка Cisco Unified Comunications с нуля. Практика03: Установка CUP
- Настройка Cisco Unified Comunications с нуля. Практика04: Установка UCCX
- Настройка Cisco Unified Comunications с нуля. Практика05: Установка шлюза MGCP FXO
- Настройка Cisco Unified Comunications с нуля. Практика06: Переход в другой домен AD
- Настройка Cisco Unified Comunications с нуля. Практика07: Полное восстановление кластера CUCM 8.6 из архива
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_01: Описание
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_02: Установка CUCM
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_03: Установка UCCX
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_04: Установка Mediasense

Добавить комментарий