
Главное меню
Навигация
Настраиваем с нуля
Цикл статей Настройка Call Manager Express CUCME с нуля:
Цикл статей Настройка Call Manager CUCM с нуля:
Comunications Apps с нуля
UCCX
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 1
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 2
- Настройка Cisco Unified Contact Center Express (UCCX) с нуля. Часть 3
- Настройка UCCX 10.x, 11.x + Cisco Finesse desktop
- Установка скрипта для записи UCCX Prompts
CUC
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 1
- Настройка Cisco Unity Connection (CUC) с нуля. Часть 2
CUP
- Настройка Cisco Unified Presence (CUP) с нуля. Теория
- Настройка Cisco Unified Presence (CUP) с нуля. Практика: Начальная установка
MediaSense
Настройка комплекта Cisco CUCM Business Edition 6000
- Настройка комплекта BE6000: Введение
- Настройка комплекта BE6000: Установка CUCM 11
- Настройка комплекта BE6000: Начальная установка CUC 11
- Настройка комплекта BE6000: Немного теории CUC 11
- Настройка комплекта BE6000: Настраиваем своего автосекретаря (IVR) в CUC 11
- Настройка комплекта BE6000: правильная Архивация CUCM 11.5
- Настройка комплекта BE6000: Восстановление CUCM 11.5 из архива
- Настройка комплекта BE6000: устанавливаем лицензии для телефонов CUCM 11.5
- Настройка комплекта BE6000: настройка конференции ad hoc CUCM 11.5
- Настройка комплекта BE6000: настройка конференции meet-me CUCM 11.5
- Настройка комплекта BE6000: настройка мониторинга комплекса CUCM 11.5
CUCM в крупном предприятии
- SRST. Теория (часть 1)
- SRST: Практика (Часть 2)
- Диалплан (dialplan) в крупной организации
- Cisco Device Mobility. Теория
- Cisco Device Mobility. Настройка
- Cisco Extension Mobility. Теория
- Cisco Extension Mobility. Настройка
- Call Control Discovery
- Настройка Multicast MOH Server на маршрутизаторах филиалов
- Cisco H.323 Gatekeeper. Теория
- Cisco H.323 Gatekeeper. Настройка и Практика
- Cisco H.323 Gatekeeper и Call Admission Control
- Практика подключения H.323 и SIP с использованием CUBE
- CUCM и LDAP Integration
DTMF и его настройка
Вы здесь
Checkpoint и кластеризация
Источник:
https://www.youtube.com/watch?v=8vMkZZZCZl4
Объединение двух Checkpoint в кластер позволяет обеспечить работу системы при сбое одной из нод этого кластера.
В общем понимании кластер должен обладать следующими свойствами: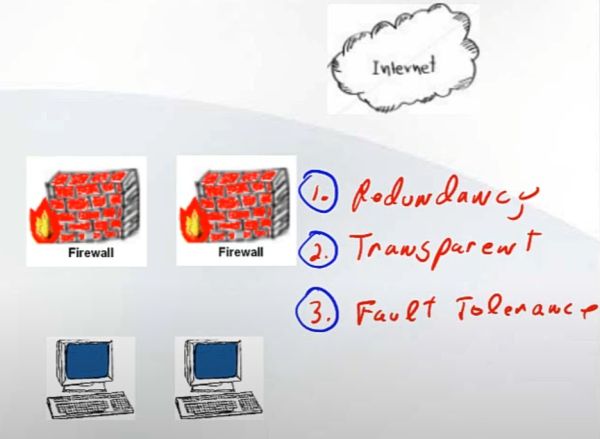
1) Redundancy - В кластере должно быть избыточное количество нод
2) Transparent - переключение в случае сбоя должно быть прозрачно для пользователя
3) Fault Tolerance - в случае сбоя переключение должно происходить автоматически
Checkpoin предлагает несколько clustering solutions:
- ClusterXL
- VRRP
ClusterXL
ClusterXL - проприетарное clustering solutions
ClusterXL может обеспечиваться двумя методами:
- High Availability - В кластере две или более ноды. Одна из них имеет Active status, вторая Standby status.
HA имеет две mode:
- Legacy mode HA (обычно не используется (основан на VRRP))
- New HA mode (поддерживается и используется) - Load Sharing / Load Balancing - В кластере также две или более ноды. Но обе ноды имеют Active status. Все ноды способны обрабатывать трафик, и способны распределять нагрузку.
- Unicast mode (простой метод)
- Multicast mode (более эффективный метод)
Во всех случаях каждая нода имеет свой IP адрес данного VLAN + один виртуальный IP, который является шлюзом для клиентов.
В случае HA виртуальный висит на Active node.
В случае Load Sharing / Load Balancing трафик попадает на виртуальный IP и далее балансируется между двумя нодами.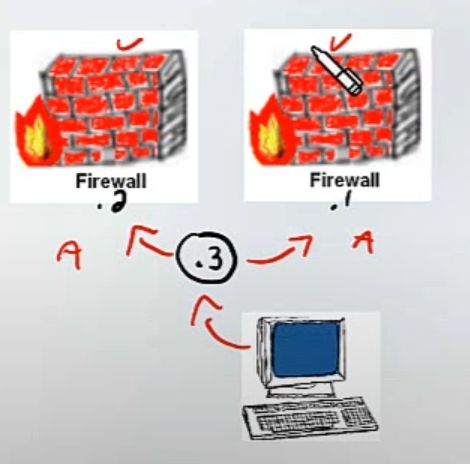
ClusterXL Basic requirements
- Железо должно совпадать с точностью до серии (например 4200 будет работать с 4400)
- OS на обоих нодах должна совпадать (например gaia)
- Версия OS должна совпадать
- HotFix на обоих нодах должны совпадать
- Аналогичные Blades настроенные на обоих нодах
- Синхронизация времени на обоих нодах. Использование NTP
State synchronization
Для обеспечения прозрачности переключения в случае сбоя, все ноды кластера должны друг с другом синхронизироваться - State synchronization.
При State synchronization все ноды кластера "знают" все текущие connections.
Для обеспечения State synchronization используется Sync cable, который соединяет ноды кластера непосредственно или через коммутатор.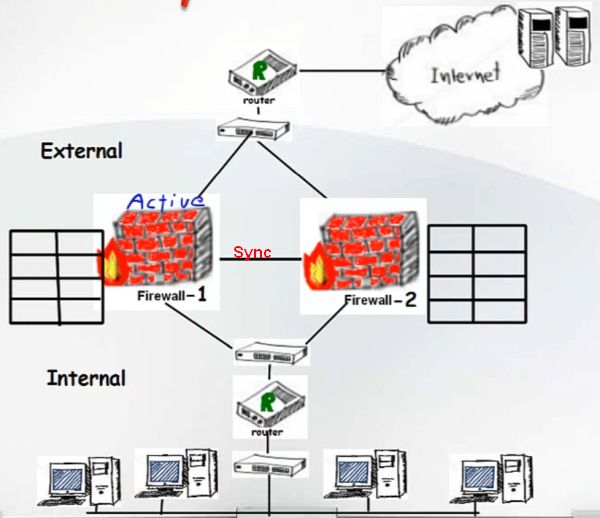
Существует два типа State synchronization:
- Full synchronization - Полная синхронизация подразумевает полноую загрузку всего Connection Table. Full synchronization происходит в случае ребута или присоединении ноды к кластеру
- Delta synchronization - Частичная синхронизация - происходит во время работы всех нод и синхронизирует вновь появляющиеся различия в Connection Table.
Cluster Control Protocol
Cluster Control Protocol или Checkpoint Control Protocol работает на всех интерфейсах, где мы включили кластеризацию.
CCP использует:
- Health Status Reports. Keepalive meassages - проверка доступности нод
- State change commands - при смене состояний active/standby
- Cluster member probing
- querying for cluster membership
- Kernel state tables
Cluster status
ноды в кластере могут находиться в следующих состояниях:
- Active
- Standby - пассивно слушает трафик от active. При необходимости становится Active.
- Down - администативно или какие то проблемы
- Active Attention - если нода последняя в Active state, и у нее проблемы. А все остальные ноды недоступны.
- Ready - разные версии софта, или разное железо
- Intializing - идет после ready, затем состояние станет Active или Standby
- ClusterXL inactive or machine down - случай когда одна из нод умерла.
Настройка ClusterXL HA
Источник https://www.youtube.com/watch?v=FRcck23stCE
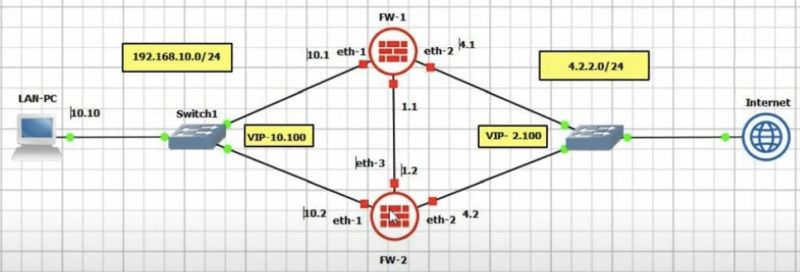
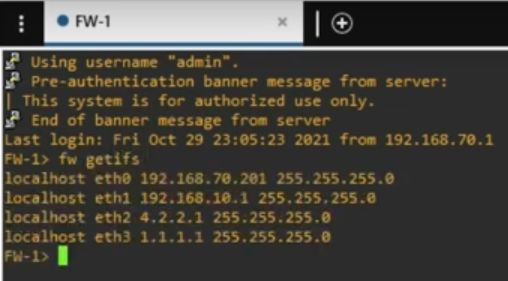
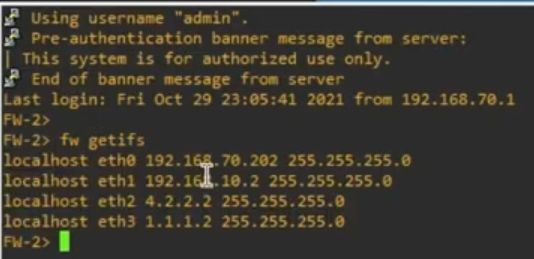
Добавляем два фаервола как показано на видео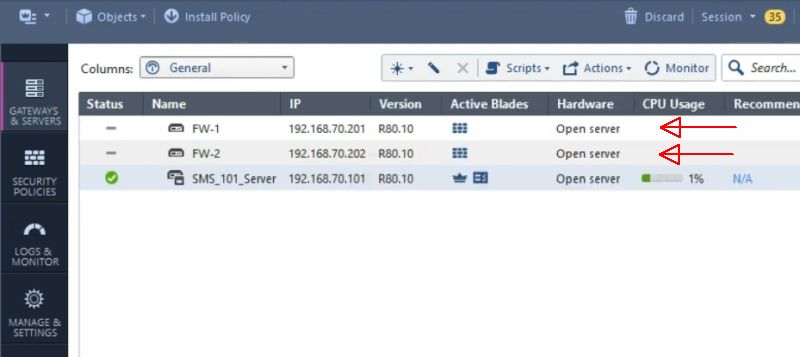
Далее добавляем кластер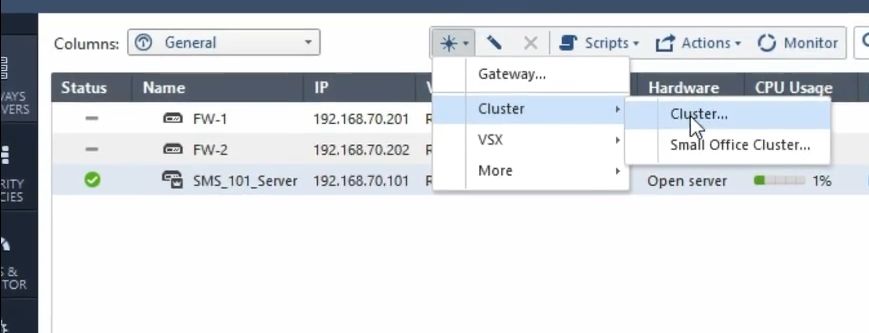
Wizard mode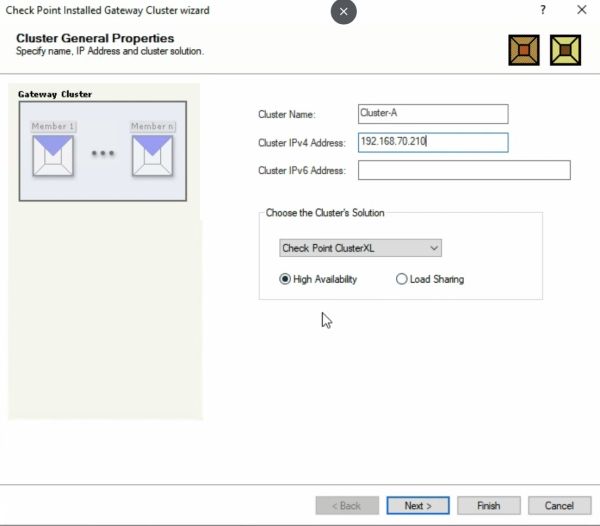
Добавляем Cluster memebers: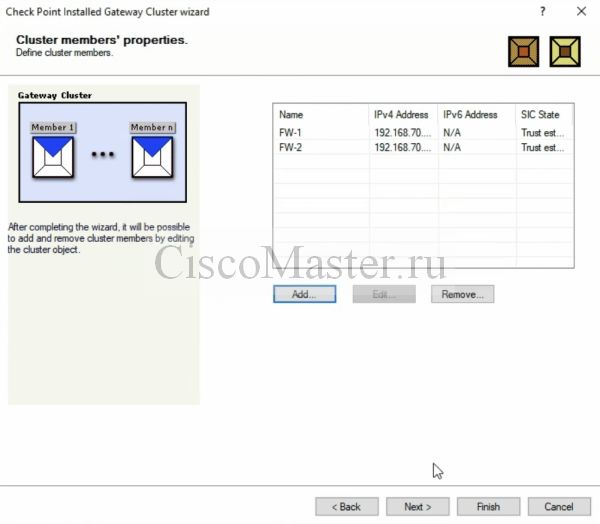
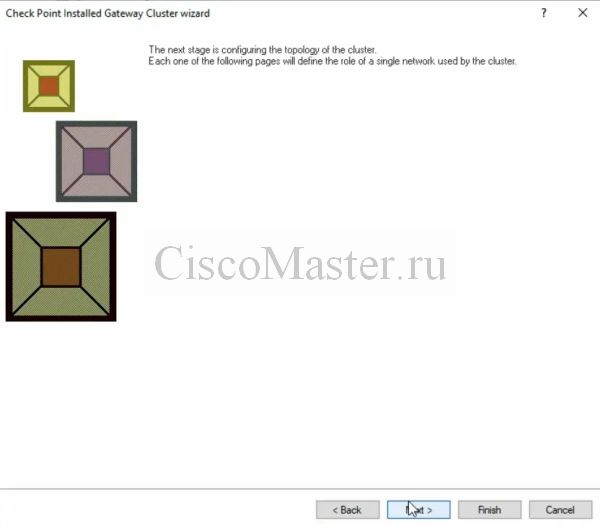
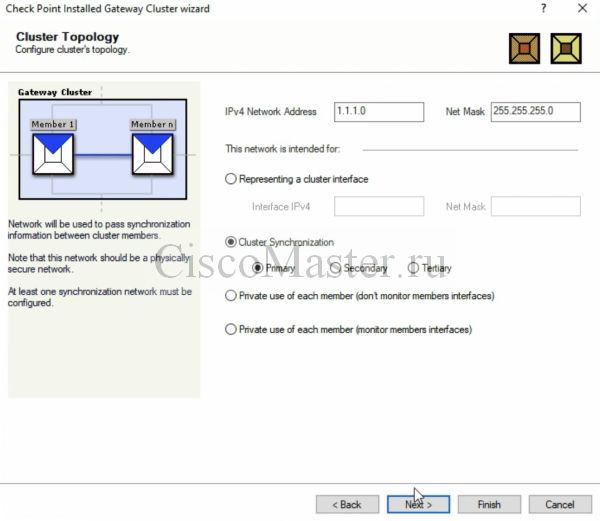
Настраиваем внешний IP кластера: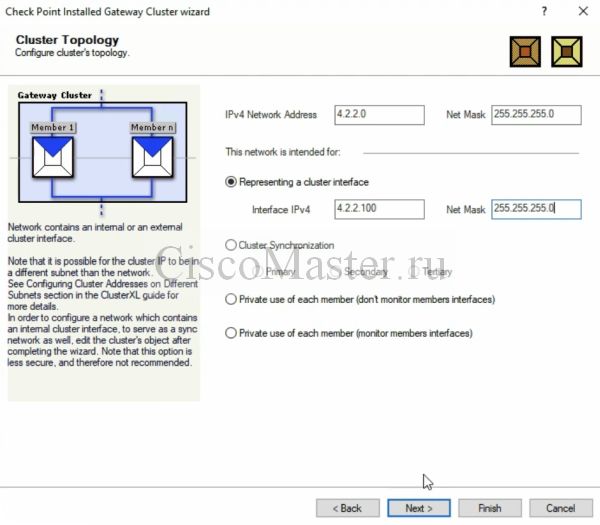
Настраиваем внутренний IP кластера: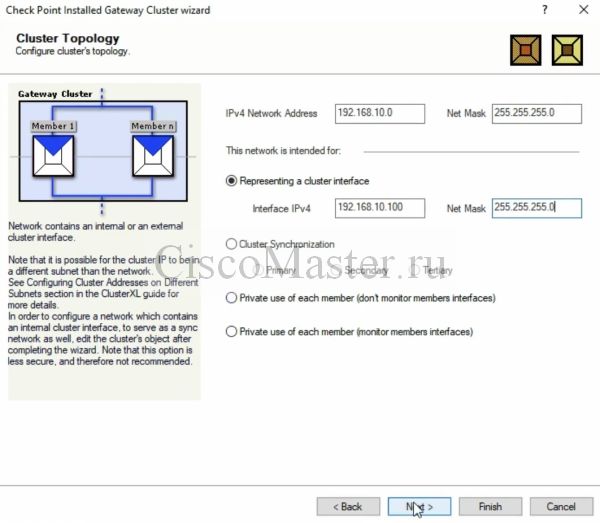
Сеть 192.168.70.0 является Management, поэтому нет необходимости включать на ней CCP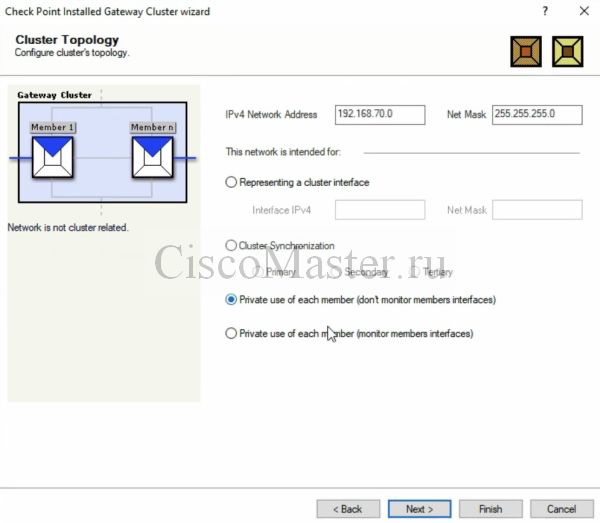
После создания кластера: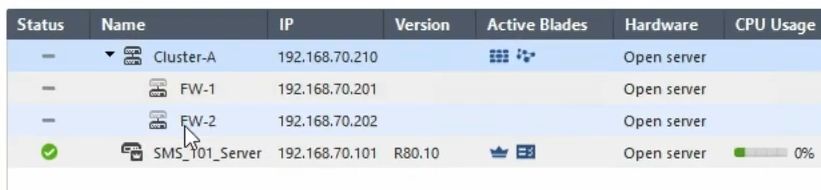
Если кликнуть на кластер, его основные настройки: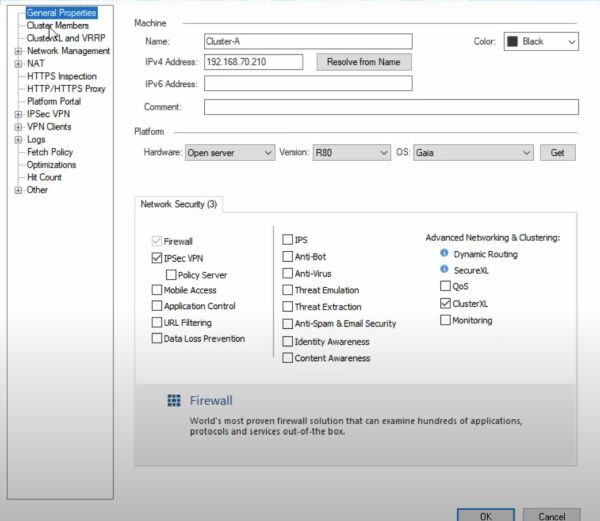
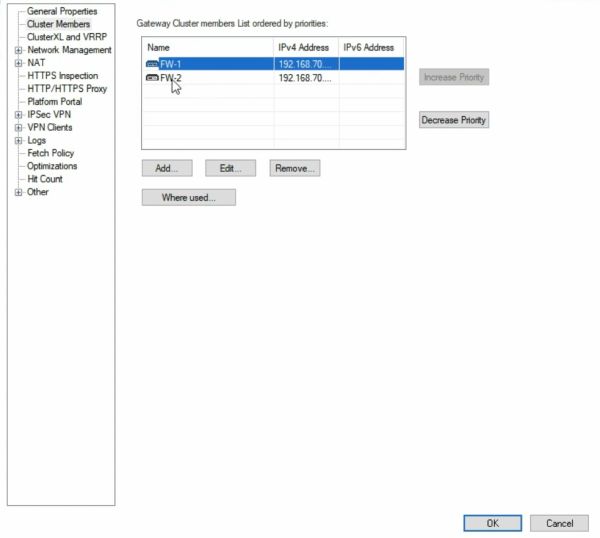
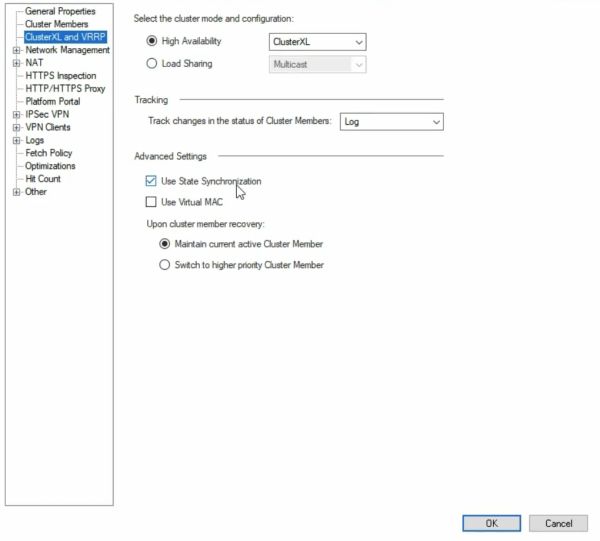
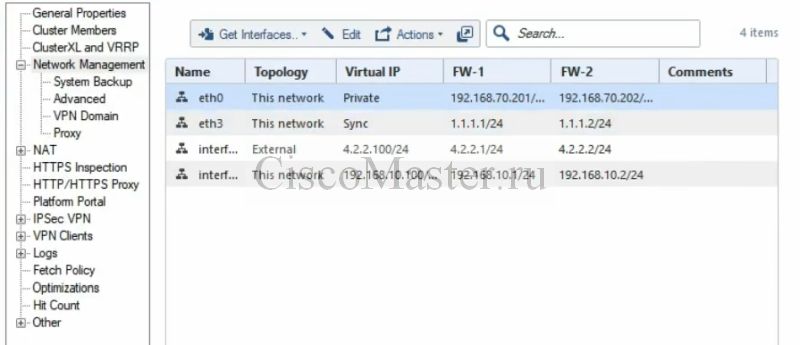
Далее делаем Publish, Install database, install Policy
Проверка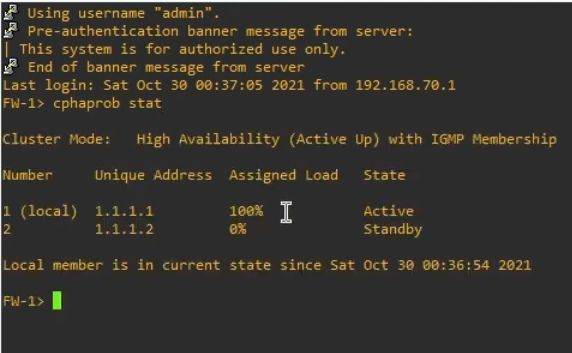
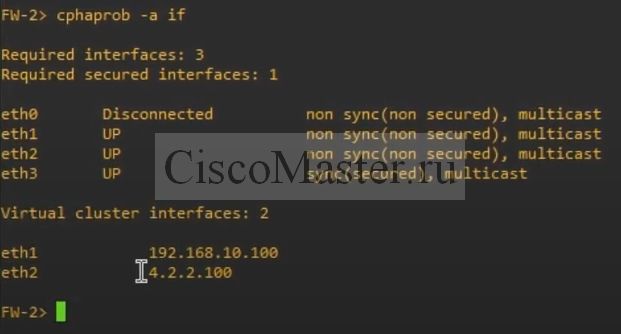
Для теста отключим внутренний интерфейс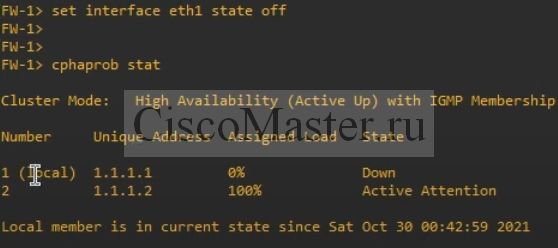
После включения всё вернется обратно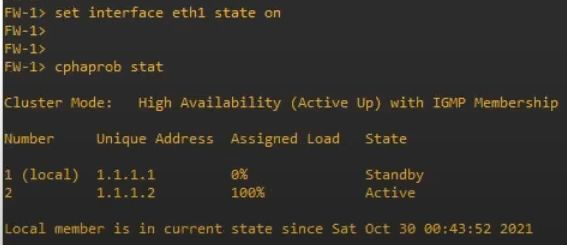
Работа с Eltex

UserGate с нуля

Security

- Cisco ISE с нуля: краткая теория (Часть 1)
- Cisco ISE с нуля: Установка ISE (Часть 2)
- Cisco ISE с нуля: Краткая теория о Authentication Policies и Authorization Policies (Часть 3)
- Cisco ISE с нуля: Wireless Authentication (Часть 4)
- Cisco ISE с нуля: Настройка Web Authentication, Guest WebAuth (Часть 5)
- Cisco ISE с нуля: настройка TACACS (часть 6)
Работа с ISE 3.2
Технологии VPN
- DMVPN и EIGRP
- DMVPN и резервный ISP
- Автопереключение между двумя провайдерами
- Подключение региональных офисов с серыми адресами по VPN
- Web VPN: подключение отовсюду
- Установка AnyConnect SSLVPN на IOS Router
- Работа с ASA Anyconnect SSL VPN HUB
- ASA и Wildcard certificate
- Настройка 3G/4G на Cisco ISR 1100 LTE 4g/3g Cellular
VoIP Voice Monitoring
VoIP Troubleshooting

- Обзор Cisco Unified Comunications System Troubleshooting
- Архивирование и восстановление Cisco Call Manager CUCM
- Поиск проблем с маршрутизацией CUCM с использованием traces
- Логирование и трекинг (trace) звонков в CUCM
- Работа с RTMT
- Полезное в RTMT
- Настройка учета звонков в CUCM
- CUCM Dialed Number Analyzer
- Полезные команды UCCX
CUCM и Факсы
Архивация и восстановление CUCM

Работа с медиа-ресурсами


SIP и Call Manager
- Часть 1 Теория
- Часть 2 Настройка SIP gateway
- Часть 3 Подключение CUCM к SIP ITSP
- Часть 6 Подключение к SIP-провайдеру
- Подключение CUCM к двум и более SIP операторам с авторизацией (sipnet + telphin). CUBE Multiple Registrars
- Подключение CUCM к SIP оператору с авторизацией по нескольким учеткам одновременно. (domru, sipnet, telphin, beeline) CUBE Multiple Registrars
- Cisco CUBE и Tenants
- Работа со "сложными" провайдерами SIP IP телефонии
Работа со стендом
- Настройка Cisco Unified Comunications с нуля. Практика01: Установка CUCM
- Настройка Cisco Unified Comunications с нуля. Практика02: Установка CUC
- Настройка Cisco Unified Comunications с нуля. Практика03: Установка CUP
- Настройка Cisco Unified Comunications с нуля. Практика04: Установка UCCX
- Настройка Cisco Unified Comunications с нуля. Практика05: Установка шлюза MGCP FXO
- Настройка Cisco Unified Comunications с нуля. Практика06: Переход в другой домен AD
- Настройка Cisco Unified Comunications с нуля. Практика07: Полное восстановление кластера CUCM 8.6 из архива
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_01: Описание
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_02: Установка CUCM
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_03: Установка UCCX
- Настройка Cisco Unified Comunications. Связка CUCM10.x_UCCX10.x_Mediasence10.x_04: Установка Mediasense

Комментарии
А соединить clusterxl с vrf
А соединить clusterxl с vrf есть такие же шаги по настройки ?
Добавить комментарий